Figure 3.4-1: Examples of structure of positions.
The genetic optimization is a very demanding computation and usually consumes a lot of processor capacity and requires a long time to produce satisfactory results. Genetic optimization in our project is designed to distribute itself over a group of computers using the services of PVM. These computers and hosted processes form so called PVM configuration. The computers do not have to be necessarily of the same architecture. If needed, the parallelization system translates various C standard types to formats required by the specific architecture (e.g. conversions between big and little endian). The user can specify how many computers should be in the configuration. The rest is fully transparent. For monitoring the current state of the parallel system and message-sending statistics see User's Manual . Parallelization layers of the system are based on Parallel Virtual Machine (PVM). For details see User's Manual section Parallel Virtual Machine).
We distinguish three types of processes :
Parent and child processes together form kernel processes or the system kernel
The two lowest layers from the object hierarchy (see Programmer's Guide) automatically establish connections between processes during initialization sequence and update connections any time a new process is spawned or ended. As soon as a communication link between two processes is created they can communicate arbitrarily. Connections maintained:
Two processes can communicate by interchanging messages. For detailed description of message format see Programmer's Guide. To address a process we use PID (Process IDentification). Messages can be sent to one process or to a group of processes at once.
Message buffering means packing a sequence of messages to one bigger message. This may produce a slight delay in delivery, but it may dramatically decrease amount of messages being sent and by this reduce the time of communication. On a network of workstations is the communication several orders of magnitude slower than computing. Moreover there is a considerable overhead connected with each message sent through the network. Thus sending one bigger message is much faster than sending more small messages. This technique is especially useful for parallelization methods, which use a huge amount of very small messages (see diffusion method). For details of buffering see Programmers Guide .
This mechanism makes possible to run the parallel genetic optimization on computers with different architectures. The problem with different architectures lies in different internal representations of various C standard types (e.g. the problem of big and little endian). Serialization makes internal representations fully transparent. The actual translation is provided by the PVM layer itself. For details of serialization see Programmers Guide .
The type of parallelization we have chosen is based on splitting of the global population to the child processes hosted on the processors of the actual PVM configuration. Each child process computes its own genetic algorithm, referred as local genetic algorithm. over its own part of the global population, referred as subpopulation. The disadvantage of this approach is that the isolated child processes cannot, in fact, much improve the optimization performance. The main task of parallelization is to provide the proper cooperation between the child processes to reduce their isolation. This cooperation is realized as an information exchange. The technique of reduction of the process isolation we call parallelization method. Our system is not specialized to a single parallelization method, but it is prepared for incorporation of a generic parallelization method (see Programmer's Guide).
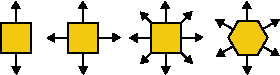
As an example of such a technique of reduction of the process isolation we have implemented the diffusion method of parallelization. The diffusion method allows the gene from a certain subpopulation to affect directly the computation of another local genetic algorithm. However, we expect quite frequent communication between the processes. This method requires each gene of the global population to be placed in a grid of positions. According to this grid each gene knows its direct neighbours (see Fig. 3.4-1 for examples). The grid of positions defines the internal structure in the global population. Every genetic operator is performed locally according to this structure. First a certain position together with its neighbourhood in the grid are chosen. Genes from this neighbourhood are chosen as arguments of the genetic operator. The resulting genes are placed back into the grid instead of some older genes selected from the previously chosen neighbourhood. In another words, a gene can affect genes only in its certain neighbourhood.
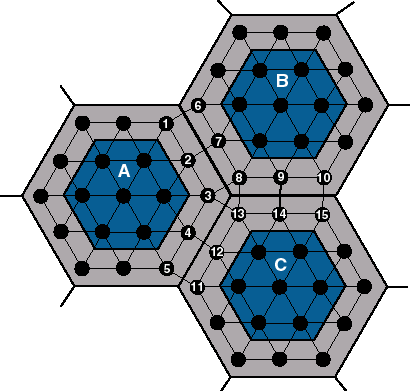
The global population is divided into subpopulations that represent
disjunctive regions of the grid. On every subpopulation a local genetic
algorithm is performed by a child process. The objective of the diffusion
method is to allow each gene to affect its neighbours, even if they are
members of another subpopulation maintained by another process. See Fig.3.4-2 for an example: the gene
2 from the subpopulation A has two neighbours in the inland of A. Also
genes 1 and 3 in the borderland of the subpopulation A and gene 7 in the borderland of
the B are direct neighbours of the gene 2. The division of the global population
into the subpopulations implies a certain structure of subpopulations:
each subpopulation knows its direct neighbours. The subpopulation is divided
into the following regions: the inland and the borderlands. The inland
represents the central part of the subpopulation (dark marked in Fig.3.4-2).
The number of borderlands corresponds with the number of direct neighbours of the child process. Each borderland consists of genes
that are close to a certain neighbour in the grid of positions e.g. the
borderland of A corresponding with neighbour B consists of genes 1, 2 and
3 in Fig.3.4-2.
Each child process maintains a shadow copy of the corresponding borderland
of each neighbour process. E.g. the subpopulation A has shadow copies of
genes 6, 7 and 8 (the borderland of B) and copies of genes 11, 12 and 13
(the borderland of C). Subpopulation B has copies of genes 1, 2, 3 and
13,14 and 15. These shadow copies are connected to the own borderlands
as in the grid of the global population. The genes in these copies are
normal members of the subpopulation, but the child process cannot change
or replace them as a result of the genetic operator. E.g. the subpopulation
A can modify all own genes (1, 2, 3, 4, 5 and other), but cannot change
the copies of the genes 6, 7, 8, 11, 12 or 13. During the computation of
the genetic algorithm the child processes exchange the information about
the changes performed on the genes in their own borderlands. According
to this information, the child processes refresh their shadow
copies of the changed genes. In fact it is not necessary to keep the shadow copies up-to-date
in every step. The messages containing the information about changes are,
in fact, very short and they can be buffered to reduce the frequency of
the communication (see subsection Message Buffering).