
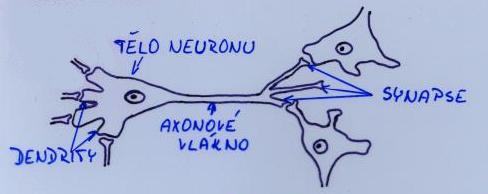
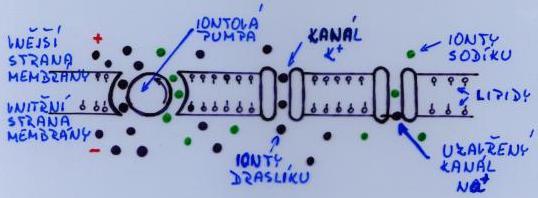
Adaptivní systém je systém se dvěma vstupy a jedním výstupem, který je popsán:
- Množinou X projevů prostředí x
- Množinou O1 informací o požadovaném chování Ω
- Množinou O2 výstupních symbolů ω
- Množinou D rozhodovacích pravidel ω = d(x, q)
- Ztrátou Q(x, Ω, q)
Q(x, Ω, q*) = minq Q(x, Ω, q)
Adaptivní systémy
Počáteční přiřazení [x, Ω] → ωs
Setrvá-li systém po dobu T na počátečním přiřazení, utrpí celkovou ztrátu TQ(x, Ω,
Je-li systém schopen měnit své chování na základě průběžného vyhodnocování ztráty, nalezne po určité době T potřebné k vyhodnocení ωr, pro které je ztráta minimální.
→ celková ztráta za dobu T
TQ(x, Ω, ωs) + (T - T)Q(x, Ω, ωr)
- Je větší než nejmenší možná celková ztráta TQ(x, Ω, ωr)
- Je menší než celková ztráta systému, který nemůže měnit své rozhodnutí TQ(x, Ω, ωs)
TQ(x, Ω, ωr) < TQ(x, Ω, ωs) + (T-T)Q(x, Ω, ωr) < TQ(x, Ω, ωs)
Učící se systémy
Uložení výsledků adaptace do paměti- Odstranění doby T potřebné k nalezení minima ztráty při opakovaném výsledku příslušného projevu prostředí
- Dále nebude třeba vyčíslovat ztráty - po naučení není nutná informace Ω o požadovaném chování
(Menší než celková ztráta adaptativního systému)
Učící se systém je systém se svěma vstupy a jedním výstupem, který je popsán:
- Množinou X projevů prostředí x
- Množinou O1 informací o požadovaném chování Ω
- Množinou O2 výstupních symbolů ω
- Množinou D rozhodovacích pravidel ω = d(x, q)
- Požadovaným chováním Ω = T(x)
- Střední ztrátou J(q) vyčíslenou na X x O1
Jeho činnost se vyznačuje tím, že po postupném předložení dvojic z posloupnosti {[xk, Ωk]}∞k=1, kde Ωk = T(xk) nalezne takový parametr q
Sekvenčnost - postupné překládání dvojic [xk, Ωk]
Induktivnost - nalézt po rpozkoumání spočetně mnoha [xk, Ωk] parametr q*, který minimalizuje střední ztrátu přes celou X.
Efektivnost adaptace a učení
Efektivnost adaptivního systému je tím větší, čím kratší je doba adaptace T a čím delší jsou časové intervaly T, během kterých nedochází ke změnám prostředí.- T / T → 0
Efektivnost AS je porovantelná s efektivností učícího se systému po naučení - T / T → 1 (T / T < 1)
AS je zhruba stejně efektivní jako neadaptivní systém - T / T ≥ 1
K adaptaci nedochází
Výběr a uspořádání příznaků
Pravděpodobnost chybného rozhodnutí X množství informace obsaženéve vstupních vzorechPříliš velký počet příznaků:
- Technická realizovatelnost
- Rychlost a zpracování
- Nebezpečí přeučení
- Korelace příznaků
Volba informativních příznaků
- Výběr minimálního počtu příznaků z předem zvolené množiny
příznaků
(nelze zaručit, že tato množina obsahuje informativní příznaky - volba závisí na konkrétní úloze) - Uspořádání příznaků v předem zvolené množině příznaků
- podle množství nesené informace - sekvenční a.
Vlastnosti Karhunen-Loeveova rozvoje
- Při daném počtu členů rozvoje poskytuje ze všech rozvojů nejmenší střední kvadratickou odchylku od původních vzorů
- Vzory jsou po použití disperzní matice po aproximaci
nekolerované
→dekolerace příznaků - Lleny rozvoje nepřispívají rovnoměrně k aproximaci - vliv každého z členů
na přesnost aproximace se zmenšuje s jeho pořadovým indexem
→ vliv členů s vysokými indexy bude malý a můžeme je zanedbat (resp. vynechat) - Velikost chyby aproximace neovlivňuje strukturu rozvoje
→ Změna požadavků na chybu aproximace nevyžaduje přepočítávat celý rozvoj
→ stačí jen přidat či odstranit něklik posledních členů
výhodné u sekvenčních metdo klasifikace
Volba vhodného zobrazení V
V: Xm → xp
tak, aby vzory z xp byly nejlepší aproximací původních vzorů z Xm ve syslu střední kvadratické odchylky.
K vzorů z jedné třídy
m příznaků
p ortonormálních vektorů ei; i = 1, .. , p v X ( p ≤ m)
→ aproximace xk z množiny Xm; k = 1, .. K
lineární kombinací vektorů ei
Yk = Suma[i = 1 .. p] ckiei
tak, aby kvadrát odchylky xk od yk
Ε2k = || xk - yk ||
byl minimální
v = ( v1, v2, ..)T
x = ( x1, x2, ..)T
y = vTx = v1x1 + v2x2 + ..
Měřeno m příznaků, z nichž chceme získat p nejdůležitějších příznaků
(1 ≤ p << m )
Matice V : p * m
( v11 .. v1p )
( . . . )
V = ( . . . )
( . . . )
( vm1 .. vmp )
Výpočet vektoru p nejdůležitějších příznaků:
y = VTx
Výpočet matice V
- "vycentrovat data"
uj = (1 / n) * Suma[i = 1 .. n]xij - Disperzní maitce pro trénovací množinu
wij = wji = (1 / n) * Suma[k = 1 .. n](xki - ui)(xkj - uj)
- Vektory, které definují nejdůležitější příznaky jsou charakteristickým vektory disperzní matice
- Charakteristická čísla odpovídají rozptylu nejdůležitějších
příznaků
→ prvním sloupcem matice V bude charakteristický vektor odpovídající největšímu charakteristickému číslu, .. - Další sloupce V se přestanou přidávat poté, co lze další charakteristická čísla vzhledem k jejich velikosti zanedbat.
Problém: Volba odpovídajícího počtu charakteristických čísel (p)
Nelze zaručit optimální volbu p vzhledem ke skutečnému významu jednotlivých příznaků. Modifikace:
- Centrované nejdůležitější příznaky
y = V'(x - u), kde
u = (u1, ..) je vektor středních hodnot - Normalizace nejdůležitějších příznaků
y = L(-1/2) V'(x - p), kde L je matice p*p, prvky diagonály jsou charakteristická čísla odpovídající sloupcům V, ostatní prvky jsou 0 - Normalizace nejdůležitějších příznaků vzhledem k
rozptylům
w'ij = wij / sqrt( wii wjj )
sqrt(X) je druhá odmocnina z X
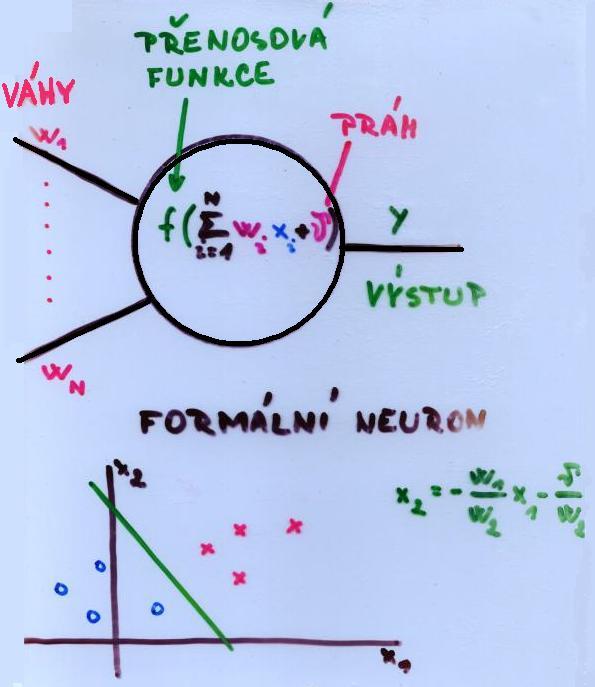
Formální neuron
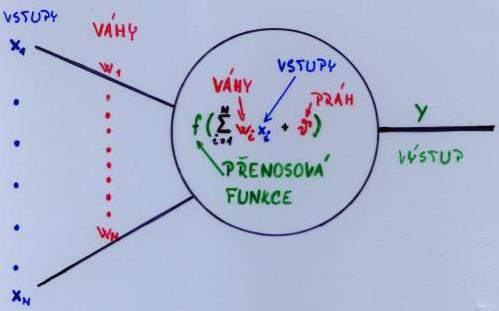
Přenosová funkce
- Skoková:
f(ξ) =- 1, jestliže ξ > 0
- 0, v ostatních případech

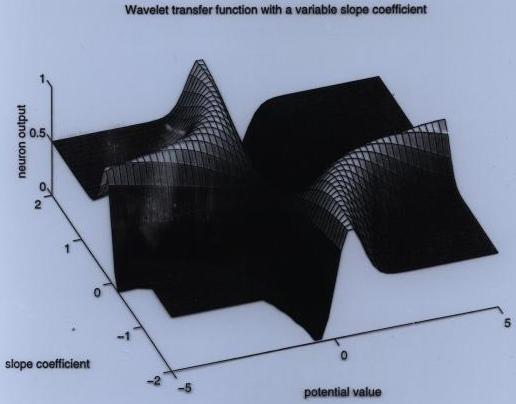
- Sigmoidální:
S(ξ) = 1 / (1 + e-ξ)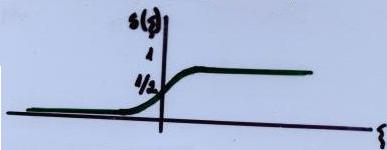
Učení
- S učitelem:
Trénovací množina - [vstup / požadovaný výstup] - Bez učitele (samoorganizace):
Chybí požadovaný výstup
Cílová funkce:
Například:
Suma[p]Suma[j] (yp,j - dp,j)2
y .. skutečný výstup
d .. požqadovaný výstup
Minimalizace střední kvadaratické odchylky v procesu učení
Rozpoznávání nově předkládaných vzorů
→ Cíl: Získat odezvu (výstup) neuronové sítě
Definice formálního neuronu
Neuron s vahami (w1, .., wn) z množiny Rn, prahem v z množiny R a přenosovou funkcí f : Rn+1 x Rn → R počítá pro libovolný vstup z z množiny Rn svůj výstup y z množiny R jako hodnotu přenosové funkce v z, f[w,v](z).
Nejčastěji se uvažuje tzv. sigomidální přenosová funkce
y = f[w,v](z) = f(ε) = 1 / ( 1 + e-ε
&epsilon = Suma[i = 1 .. n] ziwi + v označuje tzv. potenciál neuronu, R množinu reálných čísel.
Definice stavů neuronu
Nechť z označuje vstup neuronu.
- Jestliže f[w,v](z) = 1, říkáme, že je neuron aktivní
- Jestliže f[w,v](z) = 1/2, říkáme, že je neuron tichý;
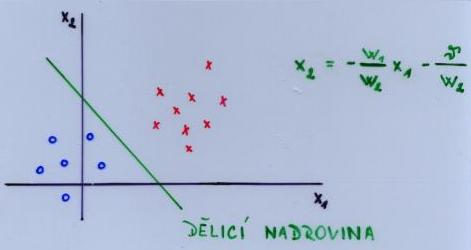
Tato skutečnost znamená, že příslušný vstup leží v dělící nadrovině určené tímto neuronem - Jestliže f[w,v](z) = 0, říkáme, že je neuron pasivní.
Definice trénovacích vzorů
Pro BP-síť B s n vstupními a m výstupními neurony:
- vstupní vzor označuje vstupní vektor x z množiny Rn zpracovávaný sítí
- požadovaný výstup d = (d1, .., dm) tvoří požadované výstupy neuronů výstupní vrstvy
- pro daný vstupní vzor představuje skutečný výstup B vektor y = (y1, .., ym) tvořený skutečnými výstupy neuronů výstupní vrstvy
Trénovaví množina T je množina p uspořádaných dvojic tvaru vstupní vzor/požadovaný výstup:
T = {[x1, d1], .., [xp, dp]}
Perceptron a lineární separabilita
D: Jednoduchý perceptron je výpočetní jednotka s prahem v, která pro n reálných vstupů x1, .., xm a váhy w1, .., wn dává výstup 1, jestliže platí nerovnost:Suma[i = 1 .. n] wixi ≥ v
(Tzn. jestliže w.x ≥ v) a 0 jinak.
Pozn.: Obdobně pro tzv. rozšířený váhový a vstupní vektor: w = (w1, w2, .., wn, wn+1); wn+1 = -v
x = (x1, x2, .., xn, 1)
→ výstup 1, jestliže w.x ≥ 0
Lineární separabilita
D: Dvě množiny A a B se nazývají lineárně separabilní v n-rozměrném prostoru, pokud existuje n+1 reálných čísel w1, .., wn, v takových, že každý bod (x1, .., xn) z množiny A splňuje:Suma[i = 1 .. n]wixi ≥ v
a každý bod (x1, .., xn) z množiny B splňuje:
Suma[i = 1 .. n]wixi < v
Příklad:
n = 2 → 14 z 16 možných boolovských funkcí je "lineárně separabilních"
n = 3 → 104 z 256 možných boolovských funkcí je "lineárně separabilních"
n = 4 → 1882 z 65536 možných boolovských funkcí je "lineárně separabilních"
Pro obecný případ zatím není znám výraz pro vyjádření odpovídajícího počtu lineárně separabilních funkcí v závislosti na n.
Absolutní lineární separabilita
D: Dvě množiny A a B se nazývají aboslutně lineárně separabilní v n-rozměrném prostoru, pokud existuje n+1 reálných čísel w1, .., wn, v takových, že každý bod (x1, .., xn) z množiny A splňuje:
Suma[i = 1 .. n]wixi > v
a každý bod (x1, .., xn) z množiny B splňuje:
Suma[i = 1 .. n]wixi < v
V: Dvě konečné množiny bodů A a B, které jsou lineárně separabilní v n-rozměrném prostoru jsou také absolutně lineárně separabilní.
Důkaz: Protože jsou množiny A a B lineárně separabilní, existují reálná čísla w1, .., wn, v taková, že platí:
Suma[i = 1 .. n]wixi ≥ v pro všechny body (a1, .., an) z množiny A a Suma[i = 1 .. n]wixi < v pro všechny body (b1, .., bn) z množiny B.
Dále nechť Ε = max{Suma[i = 1 .. n]wibi-v; (b1, .., b>sub>n) je z množiny B}.
Zřejmě Ε < Ε / 2 < 0
Nechť v' = v + Ε / 2 (Tedy: v = v' - Ε / 2)
→
- pro všechny body z A platí, že:
Suma[i = 1 .. n]wiai - (v' - Ε / 2) ≥ 0
to znamená, že Suma[i = 1 .. n]wiai - v' ≥ - Ε / 2 > 0
→ Suma[i = 1 .. n]wiai > v' (+ (a1, ..., an) z množiny A) (*) - Podobně pro všechny body z B:
Suma[i = 1 .. n]wibi-v = Suma[i = 1 .. n]wibi-(v'-Ε / 2) < 0
a tedy: Suma[i = 1 .. n]wi - v' < Ε / 2 < 0 (**)
QED
Dělící nadrovina
(pro rozšířený váhový, resp. příznakový pr.)D: Otevřený (uzavřený) pozitivní poloprostor
určený n-rozměrným váhovým vektorem w, je množina všech bodů x z množiny Rn, pro které w.x > 0 (w.x ≥ 0)
Otevřený (uzavřený) negativní poloprostor
určený n-rozměrným váhovým vektorem w je množina všech bodů x z monžiny Rn, pro které pw.x < 0 (w.x ≤ 0)
Dělicí nadrovina určená n-rozměrným váhovým vektorem w je množina všech bodů x z množiny Rn, pro které w.x =
Problém : Nalézt takové váhy (resp. práh), které by umožnily separaci (oddělení) dvou množin vzorů.
→ např. perceptronový algoritmus učení
.Předp:
A ... množina vstupních vektorů v n-rozměrném prostoru
B ... množina vstupních vektorů v n-rozměrném prostoru
→ separace A a B:
Perceptron by měl realizovat binární funkci fw tak, aby
fw(x) = 1 pro všechna x z množiny A
fw(x) = 0 pro všechna x z množiny B
(fw závisí na vahách, resp. prahu)
Chybová funkce odpovídá počtu chybně "zařazených" vzorů:
E(w) = Suma[x je z množiny A](1 - fw(x)) + Suma[x je z množiny B]fw(x)
Cíl učení: Minimalizace E(w) ve váhovém prostoru
(→ nejlépe E(w) = 0)
Perceptronový algoritmus učení - idea
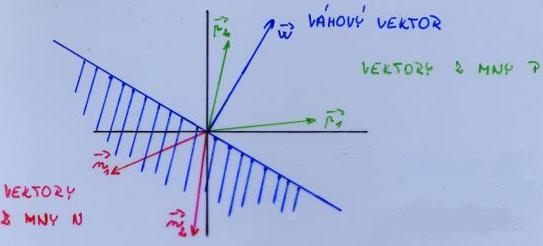
Hledáme váhový vektor w s pozitivním(P a P je třeba "odseparovat") skalárním součinem pro všechny vektory reprezentované body v P a se záporným skalárním součinem pro všechny vektory reprezentované body v N
→ Obecně: Za předpokladu, že P a N jsou množiny n-rozměrných vektorů, chceme nalézt takový váhový vektor w, že:
w.x > 0 pro všechny x z množiny P
w.x < 0 pro všechny x z množiny N
- perceptronový algoritmus učení začíná s náhodně zvoleným váhovým vektorem w0
- pokud existuje vektor x z množiny P takový, že w.x < 0, znamená to, že
úhel mezi těmito dvěma vetkroy je větší než 90o
- váhový vektor je nutné zadaptovat (~ototčit) ve směru x (tak, aby se tento vektor dostal do "pozitivního" poloprostoru definovaného w
- otočení ve směru x lze provést přičtením x k vektoru w
- pokud existuje x z množiny N a w.x >, pak je úhel mezi x a w menší než
90o
- váhový vektor je nutné zadaptovat (~otočit) směrem od x
- to lze provést odečtením x od w
→ pokud existuje řešení, lze ho nalézt v konečném počtu kroků - heuristika pro počáteční nastavení vah:
začít s průměrem "pozitivních" vstupních vektorů minus průměr "negativních" vektorů - parametr učení
- stupeň adaptivity vah ~ plasticita sítě
Perceptron - algoritmus učení
- krok: Inicializace vah malými náhodnými hodnotami wi(0); (1 ≤ i
≤ n + 1)
wi(0) ... váha vstupu v čase 0
- krok: Předložení trénovacího vzoru ve tvaru:
(x1, ..., xn+1) ... vstupní vzor
d(t) ... požadovaný výstup (pro předložený vstup)
- krok: Výpočet skutečného výstupu (odezvy sítě)
y(t) = sgm(Suma[i = 1 .. n+1]wi(t)xi(t))
- krok: Adaptace vah podle:
wi(t+1) = wi(t) - výstup je správný
wi(t+1) = wi(t) + xi(t) - výstup je 0 a měl být 1
wi(t+1) = wi(t) - xi(t) - výstup je 1 a měl být 0
- krok: Poku t nedosáhl požadované hodnoty, přejdi k 2.
kroku
Modifikace: Parametr učení m (0 ≤ m ≤ 1)
~ ovlivňuje rychlost adaptace. Adaptace vah podle:
wi(t+1) = wi(t) - výstup je správný
wi(t+1) = wi(t) + m*xi(t) - výstup je 0 a měl být 1
wi(t+1) = wi(t) - m*xi(t) - výstup je 1 a měl být 0
Konvergence perceptronového algoritmu učení (Rosenblatt - 1959)
V: Nechť P a N jsou konečné a lineárně separabilní množiny. Potom provede perceptronový algoritmus učení konečný počet aktualizací váhového vektoru wt
(Pokud se budou cyklicky testovat jeden po druhém vzory z P a N, najde perceptronový algoritmus učení po provedení konečného počtu aktualizací váhový vektor, pomocí něhož lze navzájem separovat P a N)
Důkaz: ukážeme, že perceptronový algoritmus učení přiblíží počáteční váhový vektor w0 dostatečně blízko "hledaného řešení"w*
- 3 zjednodušení - bez újmy na obecnosti
- Namísto P a N vytvoříme jedinou množinu P' = P U
N-
(N- tvoří "negované" prvky z N) - VEktory z P' budou normalizované
(jestliže byl nalezen váhový vektor w, pro který platí w.x > 0, potom totéž platí i pro každý další vektor .x, m > 0) - Váhový vektor bude také normalizovaný
(předpokládané normalizované řešení problému lineární separace budeme označovat jako w*)
- Namísto P a N vytvoříme jedinou množinu P' = P U
N-
- předpokládejme, že po t+1 aktualizacích byl vypočten váhový vektor
wt+1
→ to znamená, že po t aktualizacích byl vektor pi (z nožiny P') chybně klasifikován (pomocí váhového vektoru wt)
a tedy: wt+1 = wt + pi - kosinus úhlu u mezi wt+1 a w* je:
cos u = (w*.wt+1) / ||wt+1|| (*) - pro výraz v čitateli (*) víme, že:
w*.wt+1 = w*.(wt + pi) =
w*.wt + w*.pi)
≥ w*.wt + d,
kde d = min {w*.p, p z množiny P'}
Protože váhový vektor w* definuje absolutní lineární separaci P a N, víme, že d > 0
→ indukcí dostáváme:
w*.wt+1 ≥ w*.w0 + (t+1)*d (**)
- Na druhé straně víme, že pro výraz ve jmenovateli (*)
platí:
||wt+1||2 = (wt + pi) * (wt + pi) = ||wt||2 + 2wtpi + ||pi||2
protože wt.pi ≤ 0
(jinak by nebylo potřeba aktualizovat wt podle pi)
platí, že:
||wt+1||2 ≤ ||wt||2 + ||pi||2 ≤ ||wt||2 + 1
(protože všehcny vektory z P' byly normalizovány)
→ indukcí dostáváme:
||wt+1||2 ≤ ||w0||2 + (t + 1) (***)
- z (**) a (***) dostáváme porovnáním s (*) nerovnici:
cos u ≥ (w
→ pravá strana nerovnice roste proporcionálně s sqrt(t) a protože d > 0, mohla by být libovolně velká.
Protože ale cos u ≤ 1, musí existovat horní mez a počet aktualizací váhového vektor musí být konečný
QED
Přihrádkový algoritmus učení
Idea:
- nejlepší váhový vektor nalezený pomocí perceptronového algoritmu učení je "uložen v přihrádce"
- současně se pokračuje v aktualizaci váhového vektoru
- pokud se najde "lepší" váhový vektor, nahradí se ním vektor uložený v přihrádce
Náhodná inicializace váhového vektoru w a uložení váhového vektoru do přihrádky: ws = w
Nastavení historie uloženého váhového vektoru: hs = 0
Iterace:
aktualizace pomocí jedné iterace perceptronového algoritmu učení
aktualizace h podle po sobě jdoucích úspěšně testovaných vektorech
jestliže nastance h > hs, nahraď ws vektorem w a hs číslem h.
Pokračuj v iteraci.
Protože se bere v úvahu jen informace o posledně zvolených vzorech, může dojít i k záměně "správného" váhového vektoru za horší. Pravděpodobnost tohoto jevu by však měla klesat s rostoucím počtem iterací. Pokud je trénovací množina konečná a složky váhového a příznakových vektorů jsou racionální, lze ukázat, že přihrádkový algoritmus konverguje k optimálnímu řešení s pravděpodobností 1.