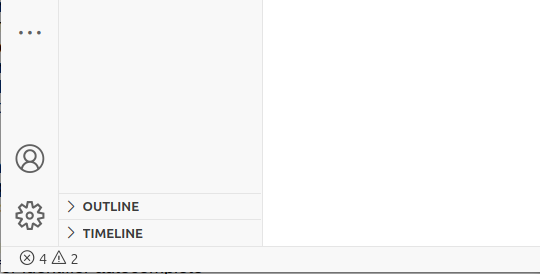
Notice that Visual Studio Code will report errors and warnings in your Python code. In the lower left corner of the window, you'll see a count of errors and warnings. For example, there are 4 errors and 2 warnings indicated here:
To see more about these errors, click the error or warning count in the lower left corner, or press Ctrl+Shift+M. Now the Problems pane will appear at the bottom of the window, showing detailed information about each error or warning:
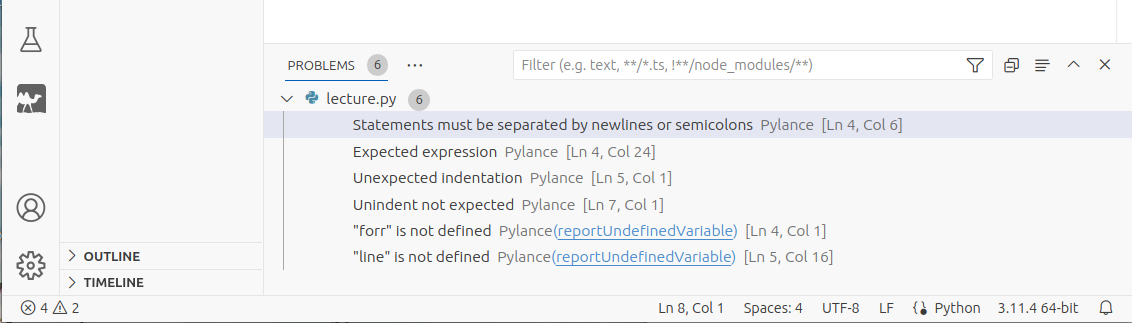
You can click on any error in the list to highlight the corresponding editor line.
You'll need to fix errors to be able to run your program. I recommend that you also always fix all warnings in your code (not only in Python but also in any programming language).
By default, Visual Studio Code enables numerous features that display extra information. For example:
The editor displays line numbers at the left edge of the window.
At the right side of the window, the editor displays a mini-map that you can use to scroll through your program:
When you type a left parenthesis or bracket, the editor automatically inserts the corresponding right parenthesis or bracket.
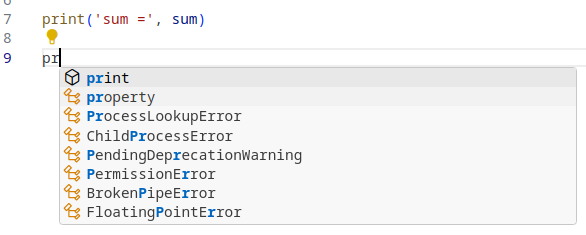
As you type any word, the editor displays a list of possible completions:
When you type a function name and a left parenthesis, the editor immediately displays documentation for the function:

If you find these features to be helpful, great. For me personally, many of them are distracting. I prefer an editor interface that doesn't display so much information, and that displays documentation only when I ask for it.
Fortunately, Visual Studio Code is highly customizable. If you want its editor to be quieter, you can use my preferred editor settings:
In the lower left, click the gear icon.
Select "Settings" to edit your settings.
In the upper right, click the small icon with an arrow ("Open Settings (JSON)").
The editor will display the file settings.json. Paste in these lines after the opening brace:
"editor.autoClosingBrackets": "never",
"editor.autoClosingQuotes": "never",
"editor.autoSurround": "never",
"editor.codeLens": false,
"editor.cursorBlinking": "solid",
"editor.guides.indentation": false,
"editor.lightbulb.enabled": false,
"editor.lineNumbers": "off",
"editor.minimap.enabled": false,
"editor.occurrencesHighlight": false,
"editor.parameterHints.enabled": false,
"editor.quickSuggestions": {
"comments": "off",
"strings": "off",
"other": "off"
},
"editor.renderLineHighlight": "none",
"editor.renderWhitespace": "none",
"editor.selectionHighlight": false,
"editor.suggestOnTriggerCharacters": false,
"editor.suggestSelection": "first",
"editor.tabCompletion": "on",
"editor.unicodeHighlight.ambiguousCharacters": false,
"editor.wordBasedSuggestions": false,
"workbench.colorCustomizations": {
"editor.wordHighlightBackground": "#00000000",
"editorError.foreground": "#00000000",
"editorInfo.foreground": "#00000000",
"editorWarning.foreground": "#00000000"
},With these settings, the editor will not display name autocompletions or function documentation automatically. If you're typing a name and want to see autocompletions, you can still get them by pressing Ctrl+Space. If you're typing a function call and want to see the function's documentation, you can still get it by pressing Ctrl+Shift+Space.
Python has boolean operators that can combine boolean values:
and
or
not
For example:
>>> True or False True >>> True and False False >>> not True False >>> not False True
We often use these boolean operators to combine comparisons:
>>> 3 < 5 and 10 < 20 True >>> not 10 <= 50 False
Python allows us to chain comparison operators. For example:
>>> x = 15 >>> 10 <= x <= 20 True
The chained comparison '10 <= x <= 20'
has exactly the same meaning as '10 <= x and
x <= 20'. You can even chain several comparison operators
together:
>>> 10 < 20 < 25 < 35 True
This has the same meaning as '10 < 20 and 20
< 25 and 25 < 35'.
Chained comparisons are especially useful when you want to test that several values are all the same:
>>> x = 5 + 5 >>> y = 2 + 8 >>> z = 1 + 9 >>> x == y == z # test whether x, y, and z are all equal True
In the last lecture, we saw that range(a,
b) represents a sequence of integers from a up to but not
including b. For example, the loop
for n in range(1, 10):
print(n)prints
1 2 3 4 5 6 7 8 9
Alternatively you may call range()
with only a single argument. range(a)
means the same as range(0, a): it will
produce the integers from 0 up to but not including a. For
example, the loop
for n in range(5):
print(n)prints
0 1 2 3 4
Notice that for any non-negative integer n, range(n)
produces n distinct numbers. And so a for
loop over range(0) will iterate 0 times,
i.e. its body will never execute. This code produces no output:
for n in range(0):
print(n)You may also call range()
with three arguments. range(a, b, c)
means the integers from a up to but not including b, stepping
by c. For example, the loop
for n in range(4, 20, 2):
print(n)produces this output:
4 6 8 10 12 14 16 18
In other words, this loop generates numbers from 4 up to (but not including) 20, adding 2 at each step.
The step value may even be negative. The loop
for n in range(10, 0, -1):
print(n)will print
10 9 8 7 6 5 4 3 2 1
In general, if c > 0 then the loop
for n in range(a, b, c):
… (body) …is equivalent to
n = a
while n < b:
… (body) …
n += c
By studying this code, you should be able to see e.g. that range(10,
20, 30) will produce just a single value (10).
Last week we learned about the break
statement, which aborts a loop. A related statement is continue,
which aborts the current iteration of a loop and continues with the
next iteration.
For example, the following loop adds up the sum of
numbers from 1 to 100. However it uses the continue
statement to skip the number 28:
sum = 0
for i in range(1, 101):
if i == 28:
continue
sum += i
print(sum)
In this particular loop, actually we could trivially replace continue
with a comparison using
'!=':
for i in range(1, 101):
if i != 28:
sum += i
However continue is sometimes convenient
in situations where more code follows it, to avoid moving all that
code into a nested block.
It's common to nest one loop inside another. For example:
for x in 'abcd': # outer loop
for y in 'efg': # inner loop
print (x + y)During each iteration of the outer loop, the inner loop will run in its entirety. This program will print
ae af ag be bf bg ce cf cg de df dg
Note that the break and continue
statements affect only the innermost loop that contains them.
For example, let's add a 'break' to the previous program:
for x in 'abcd': # outer loop
for y in 'efg': # inner loop
print (x + y)
if y == 'f':
breakThis version will produce this output:
ae af be bf ce cf de df
The break
statement aborts the inner ('for y')
loop, which causes the next iteration of the outer ('for
x') loop to run.
Python includes a few math functions that are
always available. abs(x) computes the
absolute value of x, often denoted as |x|:
>>> abs(-5) 5
round() rounds a float to the nearest
integer:
>>> round(2.3) 2
max() computes the maximum of two or
more numbers:
>>> max(10, 5) 10 >>> max(10, 5, 20, 3) 20
Similarly, min() computes the minimum of
two or more numbers:
>>> min(100, 77, 200, 88) 77
To get access to more math functions, import the math
module at the top of your program:
import math
Our Python Library Quick Reference lists various useful functions in this module, such as
sqrt(x) - square
root of x
exp(x) - return
ex
log(x) - return
loge(x)
sin(x), cos(x),
tan(x) - trigonometric functions
e, pi,
tau - mathematical constants
To use any of these functions or constants, write
"math." followed by the name.
For example:
>>> import math >>> math.sqrt(2) 1.4142135623730951 >>> math.cos(math.pi) -1.0
Our quick library reference also lists
various functions that can generate random numbers. To use these, you
must first write 'import
random'. We will often use
these as well.
A particularly useful function is
random.randint(a, b), which returns a
random integer n in the range a ≤ n ≤ b. Let's write a program
that rolls a number of 6-sided dice, and prints their sum:
import random
n = int(input('How many dice? '))
sum = 0
for i in range(n):
sum += random.randint(1, 6)
print('The total is', sum)Let's run it:
$ py dice.py How many dice? 100 The total is 337
Here's something to consider: if we roll 100 dice and compute their sum, will it usually be less than or greater than 337?
Computers store text using a coded character set, which assigns a unique number called a code point to each character. Two character sets are used in virtually all software systems today.
First, the
ASCII character set includes only 128 characters; its code
points range from 0 to 127. For example, in ASCII the character 'A'
has the number 65, and 'B' has the
number 66. 'a' has the number 97. (Code
points are often written in hexadecimal; then e.g. the code for 'A'
is 6510 = 4116, and the code for 'a'
is 9710 = 6116.)
ASCII includes all the characters you see on a standard English-language keyboard: the uppercase and lowercase letters A-Z/a-z of the Latin alphabet, the numbers 0-9 and various punctuation marks such as $, % and &. ASCII does not include accented characters such as č or ř.
You can ses a table of all ASCII characters at asciitable.com.
Note that ASCII includes various whitespace characters, which are not visible on the printed page. We will encounter some of these sometimes:
A tab character (ASCII code 9) moves the output position to the next tab stop.
A
newline character
(ASCII code 10) moves to
the next line. In Python, the escape
sequence '\n' represents
this character. In text files on Linux and macOS, each line ends
with an instance of this character.
A
carriage return
(ASCII code 13) moves to
the beginning of the line. In Python, the escape sequence '\r'
represents this character.
In text files on Windows, each line ends with a a carriage return
(13) followed by a newline (10) followed by , i.e. by the sequence
'\r\n'.
A space (ASCII code 32) is used throughout text to separate words.
As
indicated above, the representation of newlines is platform-specific
(unfortunately, for historical reasons). However, in Python
fortunately we don't usually need to be concerned with these
platform-specific representations, because when Python reads a text
file it maps any newline sequence to '\n'.
Similarly, when it writes a text file it maps '\n'
to the appropriate newline
sequence for the operating system it's running on, e.g. '\r\n'
on Windows.
The newer Unicode character set extends ASCII to include all characters in all languages of the world, including accented characters and also ideographic characters in Asian languages such as 日. Code points in Unicode range from 0 to 1,114,111.
Here is a large table at the site symbl.cc showing all the Unicode characters that exist.
Like most modern languages, Python is fully compatible with Unicode. You can write
s = 'Řehoř'
or
s = '人'and these strings will work just like strings of ASCII characters.
Python includes two functions that can map between characters and their integer code points.
Given a Unicode character c,
ord(c) returns its code point. For
example, ord('A') is 65, and ord('B')
is 66. ord('ř') is 345 (a value outside
the ASCII range).
chr() works
inversely: it maps a code point to a character. For example, chr(65)
is 'A', and chr(345)
is 'ř'.
These functions are sometimes useful when we wish to manipulate characters. For example, here's a program that reads a lowercase letter, and prints the next letter in the alphabet:
c = input('enter letter: ')
i = ord(c) - ord('a')
if 0 <= i < 26:
i = (i + 1) % 26
print('next letter is', chr(ord('a') + i))
else:
print('not a lowercase letter')
The program uses ord() to convert a
character (such as 'd') to a number
(such as 3) representing its position in the lowercase alphabet. It
then adds 1 (mod 26), and uses chr() to
map the result back into a lowercase letter.
Let's
consider more string operations in Python. First, the len()
function will give us the length of a string:
>>> len('zmrzlina')
8
We can use the [] operator to extract
individual characters of a string s. The first
character is s[0], the second is
s[1], and so on:
>>> s = 'zmrzlina' >>> s[0] 'z' >>> s[1] 'm'
The number in the brackets (e.g. 0 or 1 above) is called an index. In Python, a negative index retrieves a character from the end of the string. For example, s[-1] is the last character, and s[-2] is the second to last:
>>> s[-1] 'a' >>> s[-2] 'n'
Notice that strings in Python are immutable, meaning that they cannot change. So you cannot modify string characters:
>>> s = 'watermelon' >>> s[2] = 'x' Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'str' object does not support item assignment
A built-in operator called 'in' works on strings. When s and t are strings, (s in t) checks whether s is a substring of t:
>>> 'water' in 'watermelon' True >>> 'melon' in 'watermelon' True >>> 'xyz' in 'watermelon' False
Going further, the syntax s[i
: j] returns a
slice (i.e. substring) of elements from s[i]
up to (but not including) s[j].
Either i or j may be negative to index from the end of the sequence:
>>> s = 'watermelon' >>> s[0:5] 'water' >>> s[2:5] 'ter' >>> s[5:-1] 'melo' >>> s[-3:-1] 'lo'
In s[i : j], if the start index i is
omitted, it is 0, i.e. the beginning of the string. If the end index
j is omitted, it is len(s), i.e. the end
of the string:
>>> s[:5]'water'>>> s[5:]'melon'
The syntax s[i
: j : k] will
extract a slice of characters in which the index advances by k at
each step. For example, if we use k = 2 then we will retrieve
alternative characters:
>>> s[0:8:2] 'wtre'
Note that the step value can even be negative:
>>> s[6:2:-1] 'emre'
If the step value is negative, then an empty start index refers to the end of the string, and an empty end index refers to the beginning:
>>> s[:4:-1] 'nolem' >>> s[4::-1] 'retaw'
You can reverse a string by specifying a step value of -1, and providing neither a start or end index:
>>> s[::-1] 'nolemretaw'