The split() method is convenient for breaking strings into words. By default, it will consider words to be separated by sequences of whitespace characters, which include spaces, tabs, newlines, and other unprintable characters. It returns a list of strings:
>>> 'a big red truck'.split() ['a', 'big', 'red', 'truck'] >>> ' a big red truck '.split() ['a', 'big', 'red', 'truck']
Here's a program that reads a series of lines from standard input, each containing a series of integers separated by one or more spaces. It will print the sum of all the integers on all the input lines:
import sys
sum = 0
for line in sys.stdin:
for word in line.split():
sum += int(word)
print(sum)You may optionally pass a character to split() specifying a delimiter that separates words instead of whitespace:
>>> 'big_red_truck'.split('_')
['big', 'red', 'truck']The method join() has the opposite effect: it joins a list of strings into a single string, inserting a given separator string between each pair of strings:
>>> ' '.join(['tall', 'green', 'tree']) 'tall green tree' >>> '_'.join(['tall', 'green', 'tree']) 'tall_green_tree'
Here's a program that reads a single line, breaks it it into words, reverses the words, then prints them back out:
words = input().split() # break input into words
words = words[::-1] # reverse them
print(' '.join(words))Let's run it:
$ py rev.py one fine day day fine one $
Python includes f-strings, which are formatted strings that can contain interpolated values. For example:
>>> color1 = 'blue'
>>> color2 = 'green'
>>> f'The sky is {color1} and the field is {color2}'
'The sky is blue and the field is green'
Write the character f
immediately before a string
to indicate that it is an f-string.
Interpolated values can be arbitrary expressions. For example, consider a program that reads two values and prints their sum. Without an f-string, we might write
x = int(input('Enter x: '))
y = int(input('Enter y: '))
print('The sum of', x, 'and', y, 'is', x + y)Using an f-string, we may instead write the last line like this:
print(f'The sum of {x} and {y} is {x + y}')In my opinion, this is easier to read and write.
You may optionally specify a format code after each interpolated value to indicate how it should be rendered as a string. Some common format codes include
b – an integer in binary (base 2)
d – an integer in decimal (base 10)
x – an integer in hexadecimal (base 16)
f – a floating-point number. This format code may optionally be preceded by a period ('.') followed by an integer precision, which indicates how many digits should appear after the decimal point.
For example:
>>> import math
>>> m = 127
>>> f'hex value is {m:x}'
'hex value is 7f'
>>> import math
>>> math.pi
3.141592653589793
>>> f'pi is {math.pi:.3f}'
'pi is 3.142'Notice that Python rounds (rather than truncates) a floating-point number to a given number of digits.
You can specify a comma (',') before a 'd' or 'x' format code to specify that digits should be printed in groups of 3, with a separator between groups:
>>> x = 2 ** 100
>>> f'{x:,d}'
'1,267,650,600,228,229,401,496,703,205,376'An integer preceding a format code indicates a field width. If the value's width in characters is less than the field width, it will be padded with spaces on the left:
>>> f'{23:9d}'
' 23'
>>> f'{723:9d}'
' 723'
>>> f'{72377645:9d}'
' 72377645'If the field width is preceded with a '0', then the output will be padded with zeroes instead:
>>> f'{23:09d}'
'000000023'
>>> f'{723:09d}'
'000000723'
>>> f'{72377645:09d}'
'072377645'There are many more format codes that can you can use to control output formatting in more detail. See the Python library documentation for a complete description of these.
In the last lecture we saw various operations on lists. Now that we know about big-O running times from our algorithms class, we can discuss the big-O running time of various list operations.
Most fundamentally, getting or setting a list element by index runs in O(1), and is extremely fast. In Python, getting the length of a list via len() also runs in O(1).
Suppose that the length of a list l
is N. We may insert an element x at index i by calling l.insert(i,
x), and may delete the element at index i by running del
l[i]. Both of these operations take O(N), since they
may need to shift over many elements in memory. However, the
operation del l[-1], which deletes the
last list element, will run in O(1).
Now let's consider appending an element by calling
l.append(x), an extremely common
operation. append() runs in O(1) on average. This means that
although a single call to append() may occasionally take a relatively
long time to run, a sequence of N append operations to an
initially empty list will always run in O(N). For example, consider
this program:
n = int(input('Enter n: '))
a = []
for i in range(n):
a.append(i)This program will run in O(N), and so the average running time of each call to append() is O(1).
Occasionally we will write O(1)* to mean O(1) on average.
Finally, let's consider the time to concatenate
two lists using the + operator. If A is the length of list l,
and B is the length of list m, then (l
+ m) will run in time O(A + B). Alternatively, we may write
that it runs in O(|l| + |m|).
The important point is that this operator always builds a new
list, which takes time proportional to the new list's length.
This may have some surprising consequences. For example, consider these two programs, which differ only in their last line:
(1)
n = int(input('Enter n: '))
a = []
for i in range(n):
a.append(i)(2)
n = int(input('Enter n: '))
a = []
for i in range(n):
a = a + [i]How long will they take to run?
The first program makes N calls to append(), which runs in O(1) on average. The total time is N ⋅ O(1) = O(N).
The second program performs N list concatenations. The first builds a list of length 1; the second builds a length of 2, and so on, up to length N. Concatenating two lists to form a list of length M takes O(M). So the total time will be
O(1 + 2 + 3 + ... + N) = O(N²)
If you like, try running the two programs and entering N = 1,000,000. The first will complete instantly. The second will run for a long time. If N is 1,000,000, then a program that runs in O(N2) will be a million times slower than a program that runs in O(N) if the underlying constants are the same in both big-O functions.
The moral of the story: use append(), not concatentation, to add a single element to a list!
A list may contain any type of elements, including sublists:
>>> m = [[1], [2, 3, 4, 5], [6]]
A list of lists is a natural way to represent a matrix in Python. Consider this matrix with dimensions 3 x 3:
5 11 12 2 8 7 14 2 6
If we want to store it in Python as a list of lists, normally we will use row-major order, in which each sublist holds a row of the matrix:
m = [ [5, 11, 12], [2, 8, 7], [14, 2, 6] ]
Alternatively we could use column-major order, in which each
sublist is a matrix column; then the first sublist would be
[5, 2, 14]. The choice is
arbitrary, but by convention we will generally use row-major order.
With this ordering, we can use the syntax m[i][j]
to access the matrix element at row i, column j. Do not
forget that rows and columns are numbered from 0:
>>> m = [ [5, 11, 12], [2, 8, 7], [14, 2, 6] ] >>> m[1][0] # row 1, column 0 2
Of course, we may use the index -1 to reference the last row or the last column:
>>> m[-1][-1] = 100 >>> m [[5, 11, 12], [2, 8, 7], [14, 2, 100]]
Here's a program that will read a matrix from the input, with one row of numbers per input line:
# Read a matrix from the input, e.g.
#
# 2 3 4
# 5 1 8
# 0 2 9
import sys
m = []
for line in sys.stdin:
# build a row of the matrix
row = []
for word in line.split():
row.append(int(word))
m.append(row)
print(m)Now suppose that we want to build a zero matrix of a given size, i.e. a matrix whose elements are all 0. Recall that we may use the * operator to build a list of a given length by repeating a given element:
>>> 3 * [0] [0, 0, 0]
So you might think that we can build e.g. a 3 x 3 matrix of zeros by
>>> m = 3 * [3 * [0]] >>> m [[0, 0, 0], [0, 0, 0], [0, 0, 0]]
WARNING: This code looks correct but is not. Let's see what happens if we attempt to set the upper-left element of the matrix:
>>> m[0][0] = 7 >>> m [[7, 0, 0], [7, 0, 0], [7, 0, 0]]
It appears that several matrix elements have changed!
Here's what's going on here: all three of the sublists are actually pointers to the same list. Here is a similar example:
>>> a = [1, 2, 3] >>> m = [a, a] >>> m [[1, 2, 3], [1, 2, 3]] >>> a[0] = 7 >>> m [[7, 2, 3], [7, 2, 3]]
The line m = [a, a] creates a list with
two elements, each of which is a pointer to the list a.
When a changes, the change is visible in
m.
With that understanding, let's revisit our attempt to create a 3 x 3 matrix of zeros:
>>> m = 3 * [3 * [0]] >>> m [[0, 0, 0], [0, 0, 0], [0, 0, 0]]
This code constructs a single list with three zeroes (3
* [0]), and then repeats it 3 times, however the repetition
does not copy the list - it merely makes three pointers to the
same list. And so an update to any matrix element will actually be
visible in three places in the matrix.
Here's a correct way to make a 3 x 3 matrix of zeroes:
m = []
for i in range(3):
m.append(3 * [0])This may seem like more work, though later in this course we'll see how we can write even this form in a single line.
A tuple in Python is an immutable sequence. Its length is fixed, and you cannot update values in a tuple. Tuples are written with parentheses:
>>> t = (3, 4, 5) >>> t[0] 3 >>> t[2] 5
Essentially a tuple is an immutable list. All sequence operations will work with tuples: for example, you can access elements using slice syntax, and you can iterate over a tuple:
>>> t = (3, 4, 5, 6) >>> t[1:3] (4, 5) >>> for x in t: ... print(x) ... 3 4 5 6 >>>
The built-in function tuple() will convert any sequence to a tuple:
>>> tuple([2, 4, 6, 8]) (2, 4, 6, 8) >>> tuple(range(10)) (0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
We will often use tuples in our code. They are (slightly) more efficient than lists, and their immutability makes a program easy to understand, since when reading the code you don't need to worry about if/when their elements might change.
A tuple of two elements is called a pair. A tuple of three elements is called a triple. Usually in our code we will use tuples when we want to group a few elements together. For example, a pair such as (3, 4) is a natural way to represent a point in 2-space. Similarly, a triple such as (5, 6, -10) may represent a point in 3-space.
In Python we may assign to multiple variables at once to unpack a list or tuple:
>>> [a, b, c] = [1, 3, 5] >>> a 1 >>> b 3 >>> c 5 >>> (x, y) = (4, 5) >>> x 4 >>> y 5
In these assignments you may even write a list of variables on the left, without list or tuple notation:
>>> a, b, c = [1, 3, 5] >>> x, y = (4, 5)
On the right side, you may write a sequence of values without brackets or parentheses, and Python will automatically form a tuple:
>>> t = 3, 4, 5 >>> t (3, 4, 5)
In fact Python will freely convert between sequence types in assignments of this type. For example, all of the following are valid:
>>> a, b, c = 3, 4, 5 >>> [d, e] = (10, 11) >>> f, g, h = range(3) # sets f = 0, g = 1, h = 2
These "casual" conversions are often convenient. (They would not be allowed in stricter languages such as Haskell.)
Finally, note that variables on the left side of such as assignment may also appear on the right. The assignment is simultaneous: the new values of all variables on the left are computed using the old values of variables on the right. For example, we may swap the values of two variables like this:
>>> x, y = 10, 20 >>> x 10 >>> y 20 >>> x, y = y, x >>> x 20 >>> y 10
In fact we already used this form of multiple simultaneous assignment when we implemented Euclid's algorithm in our algorithms class a couple of weeks ago. Here is that code again:
# compute gcd(a, b)
while b != 0:
a, b = b, a % b
A list of tuples is a convenient representation for a set of points. Let's write a program that will read a set of points from standard input, and determine which two points are furthest from each other. The input will contain one point per line, like this:
2 5 6 -1 -3 6 ...
Here is the program:
import math
import sys
points = []
for line in sys.stdin:
xs, ys = line.split() # multiple assignment
point = (int(xs), int(ys))
points.append(point)
print(points)
m = 0 # maximum so far
for px, py in points:
for qx, qy in points:
dist = math.sqrt((px - qx) ** 2 + (py - qy) ** 2)
if dist > m:
m = dist
print(m)
The line xs, ys = line.split() is a
multiple assignment as we saw in the previous section. Note that this
will work only if each input line contains exactly two words. If
there are more or fewer, it will fail:
>>> xs, ys = '20 30'.split() # OK >>> xs, ys = '20 30 40'.split() Traceback (most recent call last): File "<stdin>", line 1, in <module> ValueError: too many values to unpack (expected 2)
Above, notice that a for loop may assign to multiple variables on each iteration of the loop when iterating over a sequence of sequences (as in this example). We could instead write
for p in points:
for q in points:
px, py = p
qx, qy = q
but the form "for px, py in points"
is more convenient.
The program above is a bit inefficient, since it will compute the distance between each pair of points twice. We may modify it so that the distance between each pair is computed only once, like this:
n = len(points)
for i in range(n):
for j in range(i + 1, n):
px, py = points[i]
qx, qy = points[j]
dist = math.sqrt((px - qx) ** 2 + (py - qy) ** 2)
if dist > m:
m = distThe first time the inner loop runs, it will iterate over (N - 1) points. The second time it runs, it will iterate over (N - 2) points, and so on. The total running time will be O((N - 1) + (N - 2) + ... + 1) = O(N²). So it's still quadratic, though about twice as efficient as the previous version.
Could we make the program more efficient? In fact an algorithm is known that will find the two furthest points in O(N log N). You might learn about this algorithm in a more advanced course about computational geometry.
In Python, and in almost every other programming language, we may define our own functions. As a simple example, here's a function that takes an integer 'n' and a string 's', and prints the string n times:
def printout(n, s):
for i in range(n):
print(s)
We use the keyword def to define a
function in Python. In this example, n and s are parameters to
the function. When we call the function, we will
pass values for n and s. Values passed to a function are
sometimes called an arguments. (Programmers sometimes use the
terms "parameter" and "argument" more or less
interchangeably.)
Let's put this function in a file called
printout.py. We can run Python on this
file and specify the '-i' parameter,
which means that Python should read the file and then remain in an
interactive session. In that session, we can call the function as we
like:
$ py -i printout.py >>> printout(5, 'hi') hi hi hi hi hi >>>
A function may return a value. For example:
def add(x, y, z):
return x + y + z + 10
>>> add(2, 4, 6)
22
Note that the return statement will exit
a function immediately, even from within the body of a loop or
nested loop. This is often convenient. For example, let's write a
function to determine whether an integer is prime:
def is_prime(n):
if n < 2:
return False
for i in range(2, n):
if n % i == 0: # i is a factor of n
return False # n is composite
return True # n is primeWhen we wrote this code before in our algorithms class, we used a boolean variable:
prime = True
for i in range(2, n):
if n % i == 0:
prime = False
breakWith a function, the boolean is not needed; arguably this makes the code simpler.
Consider this Python program:
x = 7
def abc(a):
i = a + x
return i
def ha():
i = 4
print(abc(2))
print(x + i)
ha()
print(x)
The variable x declared at the top is a global variable. Its
value is visible everywhere: both inside the functions abc() and
ha(), and also in the statement print(x)
at the end of the program.
The variables i declared inside abc() and ha() are local variables. They are different variables: when the line "i = a + x" executes inside abc(), that does not change the value of i in ha().
Now consider this variation of the program above:
x = 7
i = 4
def abc(a):
i = a + x
return i
print(abc(2))
print(x + i)In this version, the variables x and i declared at the top are both global. abc() declares its own local i. This is not the same as the global i. In particular, when abc() runs "i = a + x", this does not change the value of the global.
Local variables are a fundamental feature of every modern programming language. Because a local variable's scope (the area of the program where it is visible) is small, it is easy to understand how the variable will behave. In larger programs, I recommend making variables local whenever possible.
In the next lecture, we'll see some more precise rules for how Python determines which variables are local and global.
Matplotlib is a library for generating all kinds of charts and graphs. It's easy to use, and is also flexible and powerful. We'll use Matplotlib for graphing various kinds of data that we encounter this semester, especially in our algorithms class.
To use Matplotlib, you'll first need to install it on your machine. If you're running Linux, install it from the Matplotlib package provided by your distribution. For example, on Ubuntu you'll run
$ sudo apt install python3-matplotlib
On macOS or Windows, run this command:
$ pip install matplotlib
To use Matplotlib in a Python program, import the matplotlib.pyplot
package at the top of your source file. I recommend importing it
using the convenient name 'plt':
import matplotlib.pyplot as plt
To plot a curve in Matplotlib, you need to provide two sequences containing a sequence of x-coordinates and a sequence of y-coordinates, respectively. Matplotlib will plot all the points (x, y) and will draw lines between them.
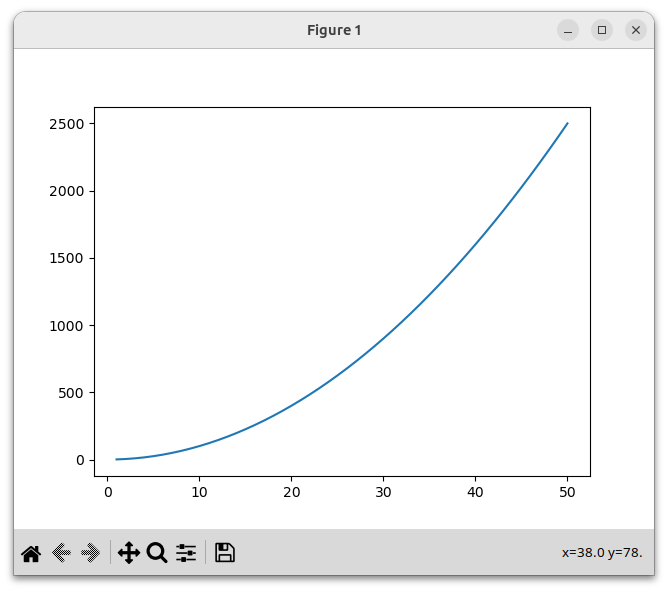
For example, let's graph the function y = x2. We'll use x-values ranging from 1 to 50, represented by range(1, 51) in Python. We need to construct a corresponding sequence of y-values. Then we can call plt.plot() to draw the curve, and plt.show() to show the resulting plot. Here is the code:
import matplotlib.pyplot as plt
xs = range(1, 51)
ys = []
for x in xs:
ys.append(x * x)
plt.plot(xs, ys)
plt.show()When we run the program, it displays this curve:
Now let's expand the program to draw the curves of two functions, namely y = x2 and y = x2 log x. We can use the same sequence of x-values for both curves, but we'll need a separate sequence of y-values for each curve. Matplotlib also allows us to specify a name for each curve, and can display a legend showing both names. Here's the updated code:
import math
import matplotlib.pyplot as plt
xs = range(1, 51)
ys = []
zs = []
for x in xs:
ys.append(x * x)
zs.append(x * x * math.log(x))
plt.plot(xs, ys, label = 'x²')
plt.plot(xs, zs, label = 'x² log x')
plt.legend()
plt.show()Let's run it:

Our Python quick reference lists the Matplotlib methods we've used here, as well as a few others. Of course, we've only scratched the surface of what Matplotlib can do. The Matplotlib web site has a page with examples of many other kinds of plots that it can create.