Some Python IDEs can perform type checking, which can report type errors in your program as you write it.
Specifically, Visual Studio Code's Pylance plugin includes Pyright, which is a type checker for Python. By default, type checking is disabled, but you can enable it via the setting "Python > Analysis: Type Checking Mode". To access this setting, click the gear menu in the lower left of the Visual Studio window, then select "Settings". Then click in the "Search settings" box at the top of the window, and type "checking" to find the setting. There are three possible checking modes: "off" (the default), "basic" and "strict".
I generally recommend enabling at least basic type checking. It will report errors such as passing the wrong number of arguments to a function, or passing the wrong type of value to a library function. For example:
from math import sqrt
def sum(a, b, c):
return a + b + c
y = sum(3, 4) # error: argument missing for parameter 'c'
z = sqrt('hello') # error: bad argument Basic type checking will not generally infer types for functions that you write. For example, consider this erroneous code:
from math import sqrt
def foo(x):
return sqrt(x) + 2.5
z = foo('hello')Clearly passing 'hello' to foo() makes no sense, but the basic type checker does not see that.
To improve the situation, we may specify a type hint (otherwise known as a type annotation) for the argument to foo():
def foo(x : float):
return sqrt(x) + 2.5
The hint indicates that the argument must be a float. And now the
type checker reports that the call foo('hello')
is erroneous:
Argument of type "Literal['hello']" cannot be assigned to parameter "x" of type "float" in function "foo" "Literal['hello']" is incompatible with "float"
A type hint may also indicate a function's return type:
def foo(x : float) -> float: # foo() takes a float and returns a float
return sqrt(x) + 2.5Note that the CPython interpreter ignores type hints! For example, consider this function:
def id(x: int) -> int:
return xIn the interpreter, we may pass it any kind of value, and no error is reported:
>>> id('hi')
'hi'
>>> id(True)
TrueNevertheless, you may want to provide type hints for some or all of your functions, for two reasons. First, as we have seen, they allow the IDE to find more bugs. Second, they are a useful form of documentation.
In fact you may use a type hint to specify the type of any variable. For example:
x: int = 4 y: str = 'yo' z: list = [3, 'hi', True] b: list[int] = [3, 4, 5]
Above, z is a list that can hold any type of value. b has type
list[int], which is a more specific type, namely a list that can hold
only integers. And so if you try to put another type of value in the
list (e.g. b.append('red')) you'll get a
type error. In type hints it's generally best to use the most
specific type possible.
We may also specify types for sets and dictionaries:
s: set[str] = { 'one', 'two', 'three' }
d: dict[int, str] = { 3 : 'red', 4 : 'blue', 5 : 'green' }The type dict[int, str] is a dictionary whose keys are ints and whose values are strings.
Now consider this function:
def abc(x: int | None):
return 7 if x == None else x + 2The type (int | None) is a union type. It indicates that x may be either an int, or None.
Generally type hints are optional in Python. However, when basic type checking is enabled, you may sometimes need to write type hints to get your programs to pass type checking. For example, consider this code:
# binary tree node class
class Node:
def __init__(self, val):
self.val = val
self.left = None
self.right = None
n = Node(3)
n.left = Node(1)
n.right = Node(5)The code is correct, however the last two lines above will not pass basic type checking:
Cannot assign member "left" for type "Node"
Expression of type "Node" cannot be assigned to member "left" of class "Node"
"Node" is incompatible with "None"
Cannot assign member "right" for type "Node"
Expression of type "Node" cannot be assigned to member "right" of class "Node"
"Node" is incompatible with "None"The problem is that the type checker believes that the 'left' and 'right' attributes have type None, so it won't allow a Node to be assigned to them. To fix this, we can add type hints to the initializer method:
def __init__(self, val):
self.val = val
self.left : Node | None = None
self.right : Node | None = NoneNow the code passes with no type errors.
Python also supports various other kinds of types (e.g. generic types) that are beyond the scope of this course. However, the set of types that we've covered should be sufficient for you to write many type hints.
Consider the following class, intended to store data about a city:
class City:
def __init__(self, name, lat, long, population):
self.name = name
self.lat = lat
self.long = long
self.population = populationThe initializer method is laborious to write. Another inconvenience is that a City's string representation doesn't show any of its attributes:
>>>c = City('Prague',50.1,14.4,1_300_000)>>> c <__main__.City object at 0x7f02e2b61d50>
We could write a __repr__ method to fix that, but that would be a further bother.
As an alternative, Python supports dataclasses, which are an easier way to write classes intended to hold data. We can write the City class as a dataclass:
from dataclasses import dataclass
@dataclass
class City:
name: str
lat: float
long: float
population: intIn a dataclass definition, we simply write each attribute's name and its type. This syntax is easy and convenient. Python automatically generates an initializer method, as well as a __repr__ method so that instances will print nicely:
>>> c = City('Prague', 50.1, 14.4, 1_300_000)
>>> c
City(name='Prague', lat=50.1, long=14.4, population=1300000)The Python interpreter (CPython) ignores the types in a dataclass definition, just like other type hints. However, the type checker will see and enforce these types. For example, the call City(1, 2.0, 3.0, 4) will produce a type error, since 1 is not a string.
You may also specify default values in a dataclass definition. For example:
@dataclass
class City:
name: str
lat: float
long: float
population: int = 0Now if we create a City and don't specify its population, it will automatically be set to zero.
Dataclasses have various other features, which you can read about in the Python documentation. But the syntax I've presented here should be enough for writing many dataclasses.
I find dataclasses to be convenient, and I often use them in my own programming.
CSV (comma-separated values) is an extremely common format for storing and exchanging data. The basic concept of CSV is that a file represents a table of data. Each line in the file represents a data record, with fields separated by commas. The first line of the file may contain the names of the fields.
Here are the first few lines of a CSV file containing data about 26,570 cities in the world:
city,city_ascii,lat,lng,country,iso2,iso3,admin_name,capital,population "Tokyo","Tokyo",35.6897,139.6922,"Japan","JP","JPN","Tōkyō","primary",37977000 "Jakarta","Jakarta",-6.2146,106.8451,"Indonesia","ID","IDN","Jakarta","primary",34540000 ...
Unfortunately the details of the CSV format may vary slightly from one file to another. In some CSV files the delimiters between fields are semicolons, tabs, or single or multiple spaces. In some files all fields are quoted; in some (as in the example above) only some are quoted, or none are. RFC 4180 attempted to standardize the format, but not all programs follow its specification.
You can use the classes csv.DictReader and csv.DictWriter to easily read and write CSV data in a Python program. When you use these classes, each CSV record is represented as a dictionary. The dictionary keys are the field names appearing in the header line at the top of the CSV file.
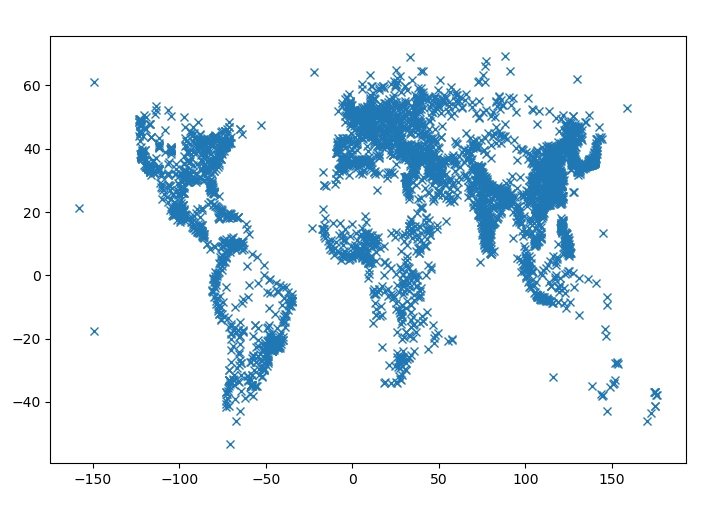
For example, let's write a Python program that will read city data from the CSV file mentioned above, and plot the longitude and latitude of each city with at least 100,000 inhabitants. We'll store each city's data using the City dataclass that we wrote in the previous section. Here is the program:
import csv
from dataclasses import dataclass
import matplotlib.pyplot as plt
@dataclass
class City:
name: str
lat: float
long: float
population: int
cities = []
with open('cities.csv') as f:
r = csv.DictReader(f)
for row in r:
pop = row['population']
if pop != '':
name = row['city']
lat = float(row['lat'])
long = float(row['lng'])
population = int(float(pop))
cities.append(City(name, lat, long, population))
top = [c for c in cities if c.population >= 100_000]
xs = [c.long for c in top]
ys = [c.lat for c in top]
plt.plot(xs, ys, 'x')
plt.show()The program produces this plot:
We see that much of the world is densely inhabited, though there are no cities in some large regions where there are deserts, jungles, or tundra.
If your program has non-hierarchical data that can be described as a series of records, I would recommend storing it in a CSV file. This format is simple and is supported by a wide variety of tools. In particular, virtually all spreadsheet programs can read data from CSV files, and it can often be convenient to read your data into a spreadsheet to view it in tabular format.
If you want to go further in working with data in Python, especially for statistics and data science, then I recommend that you learn Python's pandas library. Using pandas, you can read a table of data from a CSV file into a data frame object. You can perform many kinds of transformations and statistical operations on data frames. The book Python for Data Analysis (written by the author of pandas, and freely available online) would be a good place to start.
We now know enough Python to write larger programs. Especially when writing a larger program, we want to write code in a way that is structured, clear, and maintainable. Functions and classes are essential tools for this purpose.
Here are three general rules to follow for writing good code:
Beginning programmers often write code that looks like this:
if x > 0:
… 20 lines of code …
else:
… the same 20 lines of code, with a few small changes …Or like this:
if key == 'w': # up
… 12 lines of code …
elif key == 'x': # down
… 12 very similar lines of code …
elif key == 'a': # left
… 12 very similar lines of code …
elif key == 'r': # right
… 12 very similar lines of code …
This code is poor. It is hard to read: the differences between the parallel blocks of code may be important, but hard to spot. And it is hard to maintain. Every time you change one of the parallel blocks of code, you must change the other(s) in the same way. That is a chore, and it's also easy to forget to do that (or to do it incorrectly).
In some cases, you can eliminate this redundancy by writing code in a more general way, e.g. by looping over four possible direction vectors rather than having four blocks of code for the cases up, left, right, and down. Another useful tool is functions. You can often factor out parallel blocks of code into a function with parameters representing the (possibly small) differences in behavior between the parallel blocks. Then in place of the first code example above you can write
if x > 0:
my_fun(… arguments …)
else:
my_fun(… different arguments …)
Broadly speaking, a local variable is better than an attribute, and an attribute is better than a global variable.
The scope of a variable is the portion of a program's text in which the variable may be read or written. A local variable's scope is the function in which it appears. An attribute's scope is the class in which the attribute appears, at least if you only set the attribute in code in that class (which many languages will enforce, though not Python) A global variable's scope is the entire program. Another way of phrasing this rule is that a variable should have as small a scope as possible, which makes a program easier to understand since there are fewer places where a variable's value might change.
This rule does not apply to constants, i.e. read-only data. A global constant is unproblematic; it will never change, so its meaning is completely clear.
I recommend limiting lines to about 100 characters. Lines that are longer than this are hard to read, especially if since they may wrap in an editor window. I also recommend that you configure your editor to display a vertical gray line at the 100th column position, so that you can see if you've written a line that is too long. In Visual Studio Code, you can do that via the "editor.rulers" setting. Specifically, you can add this line to your settings.json file:
"editor.rulers": [ 100 ],
In my opinion, functions should generally be limited to about 50 lines. Functions that are much longer than this quickly become hard to understand, and are hard to read since you may have to scroll up and down to see them.
Of course, there are many best practices for writing software beyond these three basic ideas. As one example, consider the order in which functions appear in a source file, or methods appear in a class. I generally recommend ordering functions and methods from lowest-level to highest-level, in the sense that if function A calls function B, then function A will appear later in the source file. In my opinion this leads to a program that is easy to read. However, as an exception to this rule, I recommend putting the __init__ method at the top of every class, even if it calls other methods in the class.
Testing is the process of trying to discover bugs in a program and, as far as is possible, ensure that it is bug-free.
The most basic way to test your program is manually, i.e. by running it and manually entering input or using it interactively. This generally doesn't scale well to larger programs. It's also difficult to test a program thoroughly in this way.
In recent decades there has been a major trend toward automated testing. One common form of automated testing is unit tests, which test individual pieces of functionality such as individual modules, classes, methods and/or functions inside a program.
In Python, we can easily write simple unit tests using the 'assert' statement. For example, suppose that we've written a class PriorityQueue with methods add(x), remove_smallest() and is_empty(). Here is a naive implementation of this class:
# in file priority_queue.py
class PriorityQueue:
def __init__(self):
self.a = []
def is_empty(self):
return len(self.a) == 0
def add(self, x):
self.a.append(x)
def remove_smallest(self):
x = min(self.a)
i = self.a.index(x)
return self.a.pop(i)Here is a suite of several unit tests for the PriorityQueue class:
# in file test_priority_queue.py import random from priority_queue import *deftest1():q = PriorityQueue()assertq.is_empty()deftest2():q = PriorityQueue()forx in [4,2,6,5]:q.add(x)forx in [2,4,5,6]:assertnot q.is_empty()assertq.remove_smallest() == xdeftest3():q = PriorityQueue()random.seed(0)nums = [random.randrange(1000)for_ in range(100)]forx in nums:q.add(x)forx in sorted(nums):assertq.remove_smallest() == xassertq.is_empty()deftest():test1()test2()test3()print('All tests passed')
If any unit test in this function fails, the program will terminate with a stack trace revealing which test caused the problem.
Notice that test3() calls the add() method with a series of random values. Random data of this sort can be very useful for testing. The function also calls random.seed(0), which ensures that random values will be the same on each run. That means that test results will be reproducible, which is a good thing.
It's often a good idea to run all unit tests automatically each time a program is run. That ensures that you'll notice immediately if a change to the program causes a unit test to fail.
We wrote the unit tests above in pure Python, without using any libraries. To make writing tests easier, many testing frameworks are available for Python and other languages. The Python standard library contains the unittest and doctest modules, which are frameworks that you can use for writing tests. However, I generally recommend the pytest library, which you can install using pip. To use pytest, you can write tests using assert statements, as I've done in the PriorityQueue tests above. pytest will automatically discover tests implemented as functions with names beginning with "test", in source files whose names begin or end with "test". So if we are using pytest, we can delete the top-level function test() above, and simply run pytest:
$ pytest ============================= test session starts ============================== platform linux -- Python 3.11.6, pytest-7.4.0, pluggy-1.2.0 rootdir: /home/adam/Desktop/test plugins: anyio-4.0.0, xonsh-0.14.0 collected 3 items test_priority_queue.py ... [100%] ============================== 3 passed in 0.01s =============================== $
All the tests passed. Now let's intentionally introduce a bug. We'll change the last line of remove_smallest() to look like this:
return self.a.pop(i) + 1
Now let's run pytest again. Here is part of the output:
$ pytest
=========================================================== test session starts ===========================================================
platform linux -- Python 3.11.6, pytest-7.4.0, pluggy-1.2.0
rootdir: /home/adam/Desktop/test
plugins: anyio-4.0.0, xonsh-0.14.0
collected 3 items
test_priority_queue.py .FF [100%]
================================================================ FAILURES =================================================================
__________________________________________________________________ test2 __________________________________________________________________
def test2():
q = PriorityQueue()
for x in [4, 2, 6, 5]:
q.add(x)
for x in [2, 4, 5, 6]:
assert not q.is_empty()
> assert q.remove_smallest() == x
E assert 3 == 2
E + where 3 = <bound method PriorityQueue.remove_smallest of <priority_queue.PriorityQueue object at 0x7f886cb61110>>()
E + where <bound method PriorityQueue.remove_smallest of <priority_queue.PriorityQueue object at 0x7f886cb61110>> = <priority_queue.PriorityQueue object at 0x7f886cb61110>.remove_smallest
test_priority_queue.py:16: AssertionError
__________________________________________________________________ test3 __________________________________________________________________
def test3():
q = PriorityQueue()
random.seed(0)
nums = [random.randrange(1000) for _ in range(100)]
for x in nums:
q.add(x)
for x in sorted(nums):
> assert q.remove_smallest() == x
E assert 2 == 1
E + where 2 = <bound method PriorityQueue.remove_smallest of <priority_queue.PriorityQueue object at 0x7f886cb254d0>>()
E + where <bound method PriorityQueue.remove_smallest of <priority_queue.PriorityQueue object at 0x7f886cb254d0>> = <priority_queue.PriorityQueue object at 0x7f886cb254d0>.remove_smallest
test_priority_queue.py:27: AssertionError
========================================================= short test summary info =========================================================
FAILED test_priority_queue.py::test2 - assert 3 == 2
FAILED test_priority_queue.py::test3 - assert 2 == 1
======================================================= 2 failed, 1 passed in 0.01s =======================================================
$We see that one of our tests (i.e. test1) passed, and the other two (test2 and test3) failed. Without pytest, we could still run these tests using the top-level test() function that we wrote before, however the program would stop after the first failure. pytest also helpfully shows the source code of the test that failed.
In contrast to unit tests, integration tests test the functionality of groups of modules or the entire program, e.g. by sending input to the program and checking its output.
When we find and fix a bug in a program, we may write a regression test that tests that the bug is gone, and add it to our standard suite of tests for the program. That way we will find out immediately if we ever accidentally reintroduce the same bug in the future.
If a program has a graphical interface, it might not be so easy to test it in an automated way. However, if you write your program using a model-view architecture then you should be able to write automated unit tests for the model portion of your program at least.
Companies that develop software generally spend a lot of time and energy on testing, and often encourage programmers to write lots of tests. Some people have even adopted the practice of test-driven development, in which programmers write unit tests for a function or class before they implement it.
Ideally our tests will check our program's entire set of functionality. There are tools for many languages that will measure test coverage, i.e. the percentage of a program's lines that execute as the suite of tests run. For example, pytest-cov is a plugin that will produce a coverage report for tests run using pytest.
Suppose that our test suite for a program has 80% coverage. Then if there is a bug in the 20% of the lines that were not covered, the tests cannot possibly reveal it. So ideally a program's test will have 100% coverage. However, 100% coverage is often difficult to achieve, since many lines in a program may test obscure edge cases or error conditions, which may be difficult to test automatically.
Furthermore, even 100% coverage does not guarantee that tests will find every possible bug in a program. For example, consider an implementation of quicksort. We might write a single unit test that checks that sorting the array [4, 2, 6] results in the array [2, 4, 6]. This test alone is likely to achieve 100% coverage, since all of the lines of the quicksort function will run as the array is sorted. However, it is certainly possible that the implementation may have bugs which that single test case does not reveal.
To be very sure that software (or hardware) has no bugs, it is possible to write a mathematical proof of correctness of a piece of software (or hardware), and to check the proof in an automated way. However this is relatively expensive and difficult, so it's not done so often in practice. Making this easier is an active area of research.