The split() method is convenient for breaking strings into words. By default, it will consider words to be separated by any whitespace characters, which include spaces, tabs, newlines, and other unprintable characters. It returns a list of strings.
For example, here's a program that reads a series of lines from standard input, each of which can contain a series of integers separated by spaces. It will print the sum of all the integers on all the input lines:
import sys
sum = 0
for line in sys.stdin:
for word in line.split():
sum += int(word)
print(sum)The method join() has the opposite effect: it joins a list of strings into a single string, inserting a given separator string between each pair of strings. For example, here's a program that reads a single line, breaks it it into words, reverses the words, then prints them back out:
words = input().split() # break input into words
words = words[::-1] # reverse them
print(' '.join(words))
$ py rev.py
one fine day
day fine one
$ A tuple in Python is an immutable sequence. Its length is fixed, and you cannot update values in a tuple. Tuples are written with parentheses:
>>> t = (3, 4, 5) >>> t[0] 3 >>> t[2] 5
All operations that read sequences in Python will work with tuples: for example, you can access elements using slice syntax, and you can iterate over a tuple:
>>> t = (3, 4, 5, 6) >>> t[1:3] (4, 5) >>> for x in t: ... print(x) ... 3 4 5 6 >>>
The built-in function tuple() will convert any sequence to a tuple:
>>> tuple([2, 4, 6, 8]) (2, 4, 6, 8) >>> tuple(range(10)) (0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
We will often use tuples in our code. They are (slightly) more efficient than lists, and their immutability makes a program easy to understand, since when reading the code you don't need to worry about if/when their elements might change.
A tuple of two elements is called a pair. A tuple of three elements is called a triple.
A list may contain any type of elements, including tuples or sublists:
>>> l = [(2, 3), (10, 20), (5, 6)] >>> m = [[2, 4, 6], [5, 7, 9], [1, 3, 5]]
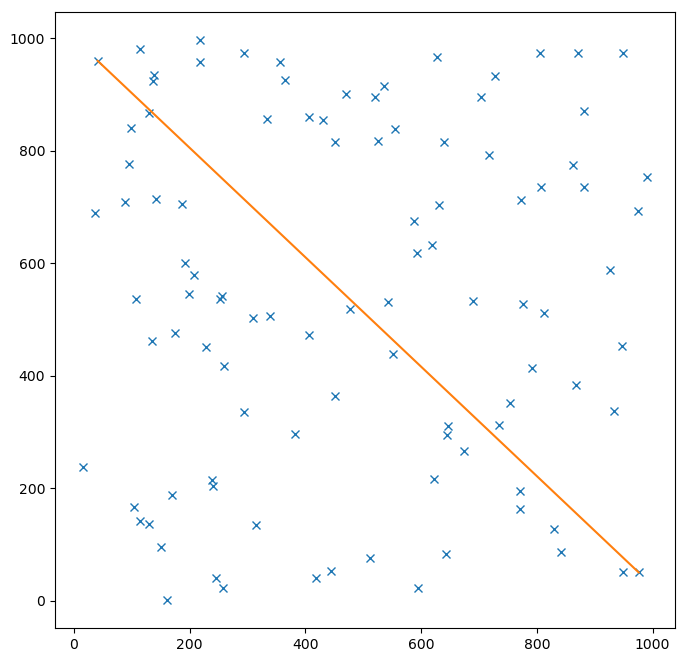
As an example, here's a program that generates 100 random points, each with an x-coordinate and y-coordinate that are randomly chosen in the range 0 .. 999. It uses a double loop to determine which two points are furthest from each other. It then plots all the points, with a line between the furthest points.
Notice that in a for loop, the expression to be assigned on each iteration can be a pattern such as (px, py). In this example, on each iteration the variables px and py will receive the x- and y-coordinates of the next point.
from math import sqrt
from random import randrange
import matplotlib.pyplot as plt
# Generate 100 random points.
points = []
xs = []
ys = []
for i in range(100):
px, py = (randrange(1000), randrange(1000)) # choose a random point
points.append((px, py))
xs.append(px)
ys.append(py)
plt.figure(figsize = (8, 8))
plt.plot(xs, ys, 'x')
# Determine which two points are furthest from each other.
greatest = -1
p1 = None
p2 = None
for (px, py) in points:
for (qx, qy) in points:
dist = sqrt((px - qx) ** 2 + (py - qy) ** 2)
if dist > greatest:
greatest = dist
p1 = (px, py)
p2 = (qx, qy)
print(greatest)
print(f'p1 = {p1}, p2 = {p2}')
px, py = p1
qx, qy = p2
plt.plot([px, qx], [py, qy])
plt.show()The generated plot looks like this:
None is a special value in Python that represents nothingness. It is often useful to represent the absence of a value.
For example, here's a program that computes the maximum of all numbers read from standard input. It keeps the maximum in a variable 'mx', which is initialized to None before any numbers are read:
import sys
mx = None
for line in sys.stdin:
x = int(line)
if mx == None or x > mx:
mx = x
print(f'max = {mx}')Be aware that the Python REPL prints nothing at all when you give it an expression whose value is None:
>>> x = None >>> x >>>
In Python, and in almost every other programming language, we may define our own functions. Here's a function that takes an integer 'n' and a string 's', and prints the string n times:
def out(n, s):
for i in range(n):
print(s)n is a parameter (or argument) to the function. When we call the function, we will pass a value for n.
Let's put this function in a file called 'out.py'. We may run Python in this file and specify the '-i' parameter, which means that Python should read the file and then remain in an interactive session. In that session, we can call the function as we like:
$ py -i out.py >>> out(5, 'orange') orange orange orange orange orange >>>
A function may return a value. For example:
def add(x, y, z):
return x + y + z + 10
>>> add(2, 4, 6)
22If a function doesn't explicitly return a value, then it will return the default value None.
Note that the 'return' statement will exit a function immediately, even from within the body of a loop or nested loop. This is often very convenient.
Here's a function to compute the factorial of a given integer:
def factorial(n):
prod = 1
for i in range(2, n + 1): # 1 .. n
prod = prod * i
return prod
We will use functions extremely often in programs that we write. Functions can call other functions, and a typical program will have many nested function calls of this sort. (A function can even call itself, which is a phenomenon called recursion that we will explore soon.)
I recommend that you limit functions to be at most about 50 lines of code, which is as many as will fit on a single screen. If a function is longer than that, I'd suggest breaking it up into smaller functions.
Consider this program:
def inc(i):
i += 1
print(i)
j = 7
inc(j)
print(j)The program will print
8 7
Here is why. First the function inc receives the value i = 7. The statement "i += 1" sets i to 8, and inc writes this value.
Now control returns to the top-level code after the function definition. The value of j is still 7! A function may modify a parameter variable to have a new value, but that does not change the corresponding value in the caller, i.e. the code that called the function. (Sometimes this is called passing by value.) And so the second number printed by this program is 7.
Now consider this variant:
def inc(l):
l[0] += 1
print(l[0])
a = [3, 5, 7]
inc(a)
print(a[0])This program will print
4 4
This program behaves somewhat differently from the preceding one, because Python passes lists by reference. When the program calls inc(a), then as the function runs l and a are the same list. If we modify the list in the function, the change is visible in the caller.
Really this is similar to behavior that we see even without calling functions:
a = 4 b = a a += 1 # does not change b a = [4, 5, 6] b = a a[0] = 7 # change is visible in b[0]
A note for more advanced students: in fact Python even passes integers by reference, though it's hard to see that since integers are immutable. Strictly speaking, when you pass any object (including an integer) to a Python function, a pointer to the object is passed by value, and so the object itself is passed by reference. (If this makes sense to you, fine; if not, don't worry about it at this stage.)
Consider this Python program:
x = 7
def abc(a):
i = a + x
return i
def ha():
i = 4
print(abc(2))
print(x + i)The variable x declared at the top is a global variable. Its value is visible everywhere: both inside the function abc(), and also in the top-level code at the end of the program.
The variables i declared inside abc() and ha() are local variables. They are different variables: when the line "i = a + x" executes inside abc(), that does not change the value of i in ha().
Now consider this variation of the program above:
x = 7
i = 4
def abc(a):
i = a + x
return i
print(abc(2))
print(x + i)In this version, the variables x and i declared at the top are both global. abc() declares its own local i. This is not the same as the global i. In particular, when abc() runs "i = a + x", this does not change the value of the global. The local i is said to shadow the global i inside the function body.
Local variables are a fundamental feature of every modern programming language. Because a local variable's scope (the area of the program where it is visible) is small, it is easy to understand how the variable will behave. I recommend making variables local whenever possible.
In the program above, what if we want the function abc() to use the global i, rather than making a new local variable? We can achieve this by declaring i as global:
x = 7
i = 4
def abc(a):
global i
i = a + x
return i
print(abc(2))
print(x + i)Now the line "i = a + x" will update the global i.
Notice that in all of the programs above, abc() is able to read the value of the global x without declaring it as global. But if a function wants to assign to a global variable, it must declare the variable as global.
To be more precise, here is how Python determines whether each variable in a function is local or global:
If there is
a global
decaration, the variable is
global.
Otherwise, if the function ever assigns to the variable, it is considered local. If not, it is considered global (and must be defined somewhere outside the function).
Note that it is impossible to write a function that uses both a local variable "x" and also a global variable "x". Each variable name such as "x" is either always local or always global within a single function body.