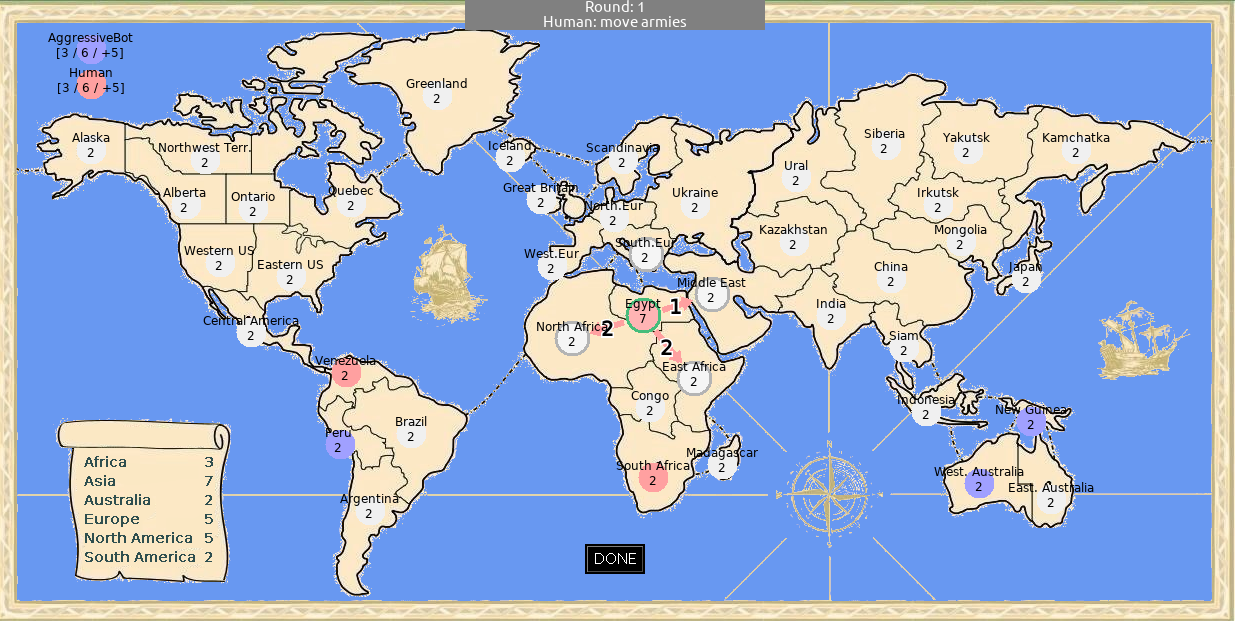
This assignment is worth 30 points and has three parts.
Download the code from the Warlight repository on GitHub. Read the game rules on the GitHub page.
Warlight-Playground/src/MyBot.java
contains a dummy bot
that moves randomly. Improve this bot so that it can defeat the
built-in AggressiveBot at least 80% of the time. You
will want to use the Warlight
API. Do not perform any state space searching at this point; we
will implement that in the following sections.
I
recommend developing MyBot incrementally. You can
launch a game between MyBot and AggressiveBot with visualization
enabled by running the main() method in MyBot.java. Watch
the moves that MyBot makes. When you see it make a move that seems
poor, update the code so that it will
choose a better move next time around. By default, the game
uses a random seed, so that every game is different. While you are
working on your bot, you may wish to set a fixed seed so that the
same random choices will occur in every game. To do that, add this
line to runInternal() in MyBot.java:
config.game.seed = 0; // use 0 or any other non-negative value as a fixed seed
To evaluate your bot, you can run a series of games between MyBot
and AggressiveBot by running the main method in the
WarlightFightConsole
class. (In that method, uncomment the line "args =
getTestArgs_1v1();" .)
Despite its fearsome-sounding name, AggressiveBot
is actually pretty dumb, and you should be able to reach an 80%
victory rate or higher without much difficulty.
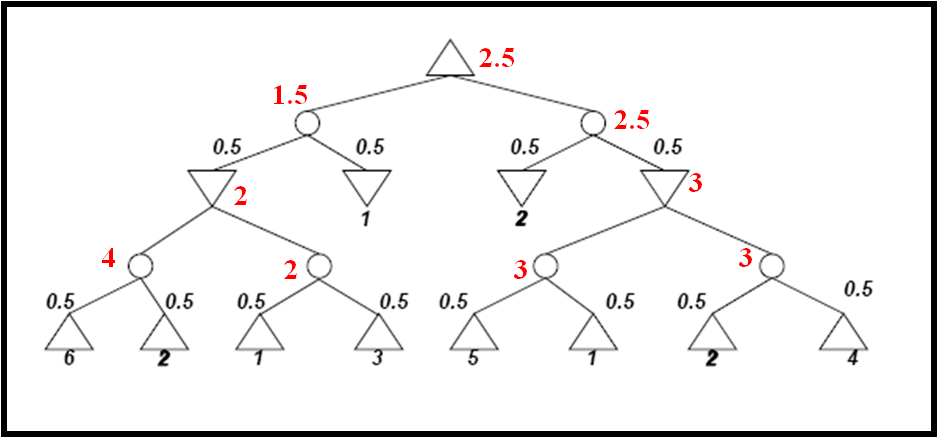
Implement either
the expectiminimax algorithm (including alpha-beta pruning)
or Monte Carlo tree search (MCTS). I will award 5 bonus points for a successful MCTS implementation.
First
clone (or update your existing copy of) the ai_1
repository. Look in the minimax/src
subdirectory, which has source files for the classes described in
this section.
Write a general-purpose implementation that can search any game that implements the following interface:
// S = state type, A = action type
public interface Game<S, A> {
S initialState();
S clone(S state);
int player(S state); // which player moves next: 1 (maximizing) or 2 (minimizing)
void apply(S state, A action); // apply action to state, possibly with stochastic result
boolean isDone(S state); // true if game has finished
double outcome(S state); // 1.0 = player 1 wins, 0.5 = draw, 0.0 = player 2 wins
}Your expectiminimax or MCTS class will implement this interface:
interface Strategy<S, A> {
A action(S state);
}A Strategy represents a strategy for playing a game. It is essentially a function which, given a state, decides what action the current player should take.
You must implement your algorithm so that it will work even if moves do not strictly alternate. For example, in some games player 1 might move twice, then player 2 might move twice, and so on. (Warlight is like this, since on each player's turn they have two moves: one to place armies and one to attack/transfer.)
For expectiminimax, you will need these additional interfaces:
interface ActionGenerator<S, A> {
List<A> actions(S state); // actions to try in this state
}
class Possibility<S> {
public double prob; // probability from 0..1
public S state;
}
interface ResultGenerator<S, A> {
List<Possibility<S>> possibleResults(S state, A action); // possible results of an action
}
public interface Evaluator<S> {
double evaluate(S state);
}The ActionGenerator and ResultGenerator interfaces exist because the Game interface does not have methods to return all possible actions at every state, or all possible results from any action. Such methods would be impractical, since Warlight's branching factor is so high. There may be many thousands of possible actions or results at any moment, and our algorithms cannot explore all of these. Instead, these interfaces are intended to return a small number of possible actions or results, chosen strategically and/or at random, as if the game's branching factor was much smaller. So these interfaces implement a (somewhat unfortunate) compromise to deal with the high branching factor.
Because these interfaces are separate from the main Game interface, you can test (for example) two strategy variants against each other that use two different ActionGenerators.
You should implement the following class in
Expectiminimax.java:
class Expectiminimax<S, A> implements Strategy<S, A> {
public Expectiminimax(Game<S, A> game,
ActionGenerator<S, A> actionGenerator,
ResultGenerator<S, A> resultGenerator,
Evaluator<S> evaluator, int limit) {
…
}
}
In the Expectiminimax constructor:
actionGenerator
is an object that can generate possible actions at each node.
resultGenerator is an
object that can generate possible results of each action.
evaluator provides a heuristic
evaluation function that
can estimate the expected outcome of the game at any node. As
described in section 5.4 "Imperfect Real-Time Decisions"
of our text (Russell & Norvig), you will need to use this
evaluation function when you cut off the search because it has
reached its maximum depth.
If limit
is a positive number, it
represents a search depth. For example, if limit
is 2, your action
method should consider all
possible sequences of 2 actions from the given state. If
limit is negative, its absolute value
is the maximum time to
spend searching, in milliseconds.
Your method must
return before this limit
expires. If limit is
zero, there is no time or depth limit and you should search the
entire game tree.
Please implement alpha-beta pruning at least for max and min nodes in the search tree. You can optionally implement alpha-beta pruning even for chance nodes as described in section 5.5.1 of our text, but that is not required.
When there is a time limit, use iterative deepening. If the time limit expires, abort the current iteration and return the best move from the previous iteration.
The Java method System.nanoTime() retrieves the number of nanoseconds since some (unknown) past fixed moment. If you call nanoTime() at some moment and then call it again later, the difference between the returned values will tell you how many nanoseconds elapsed between the two calls.
At a leaf node representing a completed game, it's best to call the outcome() method to find the node's value. (In theory evaluate() should return the same value for a completed game, but that is not guaranteed.)
First, a word of warning: MCTS is a bit tricky to implement. Nevertheless it is an interesting algorithm, and you may attempt to implement it if you are up for the challenge.
You may want to follow the pseudocode of Algorithm 2 in this survey paper:
Cameron Browne et al, "A Survey of Monte Carlo Tree Search Methods" (2012)
The following paper is more approachable and may also be useful, though its pseudocode is less precise:
Mark Winands, Monte-Carlo Tree Search in Board Games (2016)
Your MCTS implementation will use the
ActionGenerator and
ResultGenerator interfaces
described in the expectiminimax section above. Implement the
following class in Mcts.java:
// Monte Carlo tree search
class Mcts<S, A> implements Strategy<S, A> {
public Mcts(Game<S, A> game, Strategy<S, A> base,
ActionGenerator<S, A> actionGenerator, ResultGenerator<S, A> resultGenerator,
int limit) {
…
}
}
In the Mcts constructor:
base is a strategy implementing
the default policy to be used for simulations. (See sections
1.1 "Overview" and 3.1 "Algorithm" in the Browne
paper.)
If limit
is a positive number, it
represents the number of iterations to peform. Each iteration
includes a node expansion and a playout. If limit
is negative, its absolute value
is the maximum time to
spend searching, in milliseconds.
Your method must
return before this limit
expires.
Be sure to clone the game state when you begin a simulation from that new new node.
The Java method System.nanoTime() retrieves the number of nanoseconds since some (unknown) past fixed moment. If you call nanoTime() at some moment and then call it again later, the difference between the returned values will tell you how many nanoseconds elapsed between the two calls.
I recommend implementing a minimax tree, in which each node's total reward Q represents an absolute outcome (e.g. 1.0 is a win for player 1 and 0.0 is a win for player 2). With this approach, then if it is player 2's turn at node v, then in the BestChild function you need to look for a minimal value rather than a maximal value since player 2 wants to minimize. When you do so, you should subtract the exploration term rather than adding it:
`"return" underset(v' in "children of " v)("argmin") (Q(v'))/(N(v')) - c sqrt((2 ln N(v)) / (N(v'))`
When performing backpropagation, do not use Algorithm 3 "UCT backup for two players" from the Browne paper, which is appropriate only for a negamax tree. (You could alternatively implement a negamax tree, but it may not be a great fit for this assignment since moves may not be strictly alternating.)
You will need to use some variation of MCTS that can handle stochastic behavior. Here are two possibilities:
Create chance nodes in the MCTS tree as described (briefly) in the Winands paper. Minimax nodes and chance nodes will alternate in the tree. As you traverse down the tree during the selection phase, each time you encounter a chance node you must choose a child node representing one possible stochastic outcome. Try to balance these choices so that the number of visits to each child node is proportional to the probability of the outcome it represents.
Use determinization (mentioned in section 4.8.1 in the Browne paper). Create a separate MCTS tree for each determinization, making sure that all trees have the same top-level set of actions. You can think of each determinization as a non-stochastic world in which the pseudo-random result of any action is known in advance to both players. Run the algorithm in these trees in round-robin fashion, moving to a new tree on each iteration. After these runs have completed, each determinization will have values N (number of simulations) and Q (total reward) for the nodes below each top-level action. Combine the results from all determinizations in some way to determine a final action.
You could even attempt to implement more features described in the papers above (e.g. progressive widening), though this will quickly take you into more advanced territory.
The ai_1 repository contains two simple games that implement the interfaces above: Tic-Tac-Toe and Pig. Each includes several sample strategies. The classes ExpectiminimaxTest and MctsTest will run your expectiminimax or MCTS implementation on these games. It would be wise to make sure you can pass these tests before tackling Warlight in the next section.
Note that Tic-Tac-Toe is not stochastic, but you can still play it with expectiminimax or MCTS - there is just one possible result of every action.
Write a Warlight bot SearchBot that
uses your expectiminimax or MCTS implementation to search through the
Warlight state space.
You will need to do the following:
Write a class WarlightGame
implementing Game<S, A>. You should use
the Warlight classes GameState and Action
as your state type S and action type A, so your class will implement
Game<GameState, Action>. Your class might look
something like this:
class WarlightGame implements Game<GameState, Action> {
@Override
public GameState initialState() {
return new GameState();
}
...
}
Write a class WarlightActionGenerator
implementing ActionGenerator<S, A> with an
actions() method that can propose several possible
actions for every state. In the actions() method, call
state.getPhase() to determine which kind of actions you
need to generate.You should choose these somewhat strategically,
e.g. by adding some
randomness to the strategy you implemented in MyBot
in part 1.
Implement
a class WarlightResultGenerator
that
implements ResultGenerator<S,
A> and
returns a set of possible
results for any action. I recommend that you create several clones
of the given state (e.g. 4) and run the Action.apply
function once on each clone. That will give you 4 different possible
results. You can then say that each possible result has probability
0.25.
This will give you a crude approximation to the possible outcomes.
By increasing the constant 4,
you will get a better approximation, but will also increase the
branching factor. Also notice that an action that chooses a starting
region or places armies has only 1 possible result, so you should
return only a single result for
such actions. (Note: if you are using MCTS with determinization,
this class will never be used,
so you can just implement it with a dummy method.)
If you are using expectiminimax, you
will need to invent an evaluation function for Warlight board
states. Write a class WarlightEvaluator
with a method evaluate()
containing this function, which should return a float from 0.0 to
1.0 roughly indicating the probability that player 1 will win. Here
is one approach you might take:
let a = (armies owned by player 1) – (armies owned by player 2)
let r = (regions owned by player 1) – (regions owned by player 2)
let t = (armies player 1 receives per turn) – (armies player 2 receives per turn)
return f(Ca · a + Cr · r + Ct · t), for some constants Ca, Cr, Ct, where f is the standard logistic function
If you are using MCTS,
you will need a base strategy to be used for simulations, i.e.
rollouts. Place this strategy in a class BaseStrategy.
You could use a strategy that plays randomly, but it may
be better to use the strategy
that you wrote in part 1 above.
Write a bot SearchBot
derived from Bot
that uses your Expectiminimax
or Mcts
class to play Warlight. In your bot's init()
method,
generate an instance of Expectiminimax
or Mcts. In the bot's
chooseRegion(), placeArmies() and moveArmies() methods, use this
instance's action() method to decide what to do.
Once your bot is working,
evaluate its performance. Can it defeat your original MyBot
from part 1? Does it perform better against AggressiveBot
than MyBot
did? In other words, does the lookahead tree search give you any
benefit?
In my experiments, I've found that my MCTS-based bot can defeat my base strategy bot 70-80% of the time when given 200 ms of thinking time per move. I'm using chance nodes in the MCTS tree (the first of the two stochastic options described above) and these parameters:
4 random strategic actions for each state
4 random results from each attack/move action
exploration constant Cp = `sqrt(2)`
To receive credit for this part of the assignment, your SearchBot must be able to defeat AggressiveBot at least 80% of the time. (I have not set this threshold any higher than for part 1, since I recognize that it may be challenging to make your bot perform well, especially for expectiminimax.)
You will probably want to experiment with various parameters of your implementation. For either search method (expectiminimax or MCTS), you may wish to experiment with
number (and nature) of actions proposed for any state
number (and nature) of
possibilities returned by ResultGenerator.possibleResults()
For expectiminimax, you can also tune
search depth
evaluation function
For MCTS, you may want to experiment with
search time
number of determinizations
base strategy
exploration constant Cp
If you have two variations of your strategy, you
can test
them versus each other either using the
Runner
class
in
the ai_1 repository, or by running
WarlightFightConsole.
All entries received before the deadline for this assignment will automatically entered into a tournament in which your bots will play each other. In the tournament, each bot will have up to 0.5 second to make each move. When I run the tournament I'll use a slightly higher hard limit such as 0.6 seconds, so don't worry about going a few milliseconds over 0.5 second. If a bot fails to respond in time, it will make no move that turn, but will not automatically lose the game. Each bot will play several games against every other bot, both as player 1 and as player 2.
I will accept only single-threaded bots since the focus of this class is algorithms, not multi-threaded programming.
Your tournament entry does not have to use a tree search! If your hand-coded bot performs better or you want to use some other algorithm, that is fine too.